So then from my understanding, you want to put R1 and R3 into their own sub-AS, correct? Well, I wasn’t sure about this so I went in and labbed it up. The fundamental question here is, can two BGP routers be put into the same sub-AS if they are not directly connected, that is, if they have to pass through another sub-AS to reach each other.
Typically, BGP routers can become neighbors even if they’re not directly connected. In the case of iBGP, this is true without any additional configurations. For eBGP, you need to add features such as multhop.
Now, what about iBGP routers within the same sub-AS? Do they need to be directly connected or can they become neighbors if they can communicate through another sub-AS? Well, it seems that they cannot. iBGP routers that belong to the same sub-AS must connect to each other either directly, or via another iBGP router in the same sub-AS. I’ve labbed it up and confirmed it.
So it seems that for your topology, the only solution is to either connect R1 and R3, or don’t create another sub-AS.
My topology is like that:
requirement:
R4->R5 is reachable
R5->R4 is reachable
R1,R21,R22,R3 should be within iBGP AS 123.
R4 is AS4. eBGP peer with AS123.
R5 is AS5. eBGP peer with AS123.
I don’t care about if R1 and R3 should be inside the same sub-AS or not.
I just like R4 and R5 reachable to each other and nothing else.
But I am not sure about the exact configuration of them(R1,R21,R22,R3(or even R4 or R5 if they are not simply eBGP))
Based on your explanation, in order to get your topology to work with your requirements, you do not need to implement confederations at all. (The dark inner rectangle encompassing R21 and R22 was confusing, it looked like a sub-AS).
To achieve it you will need:
A full mesh of iBGP peerings within AS 123
eBGP peerings between R4 and R1 as well as between R5 and R3.
Either static routing or a dynamic routing protocol such as OSPF between all routers in AS123 to make them all reachable to each other
Advertising of the appropriate networks by all the BGP routers to ensure convergence.
For such a configuration, you can follow the configuration in the following lesson:
The topology is actually almost the same as the one in your post, except that there are 3 routers in the middle AS instead of your four.
Take a look at that, try it out, and if you run into any specific problems, please let us know!
A route reflector is not required in such a topology. It can be used if you like, but it is unnecessary.
Remember, a route reflector solves the problem of the requirement of full mesh peerings between iBGP routers within a single AS when there are many routers. How many is “many routers”? I would say dozens or even over one hundred. It also depends upon the number of prefixes being shared as well, which increases the demand on CPU and memory resources on the devices.
Although you can configure a route reflector, the topology is nowhere near large enough to actually need one. More info on route reflectors can be found at this NetworkLessons note on the subject, as well as at the following lesson:
My question is since we are using ibgp and ospf, do we need to redistribute routes from ospf within ibgp on the router towards BGP? i have created a topology similar to discussed, i am able to see peering formed between ibgp peers, all routers configured ospf area 0. and eBGP peers formed between r1 and cata3 and 4. but not seeing any prefixes exchanged on any bgp
The IGP that you use within an AS (such as OSPF) should remain only within that AS. There should be no redistribution of IGP routes into other ASes. In this particular case, OSPF should share all routes within your AS2, and only eBGP should be used to share routes between AS2 and AS1000. This is best practice, and it is also the very reason why BGP was created.
Now having said that, why would R1 not contain any of the prefixes advertised within AS2? Well, first I see that your BGP peerings look correct, with the correct AS numbers. I suggest you take a look at the following:
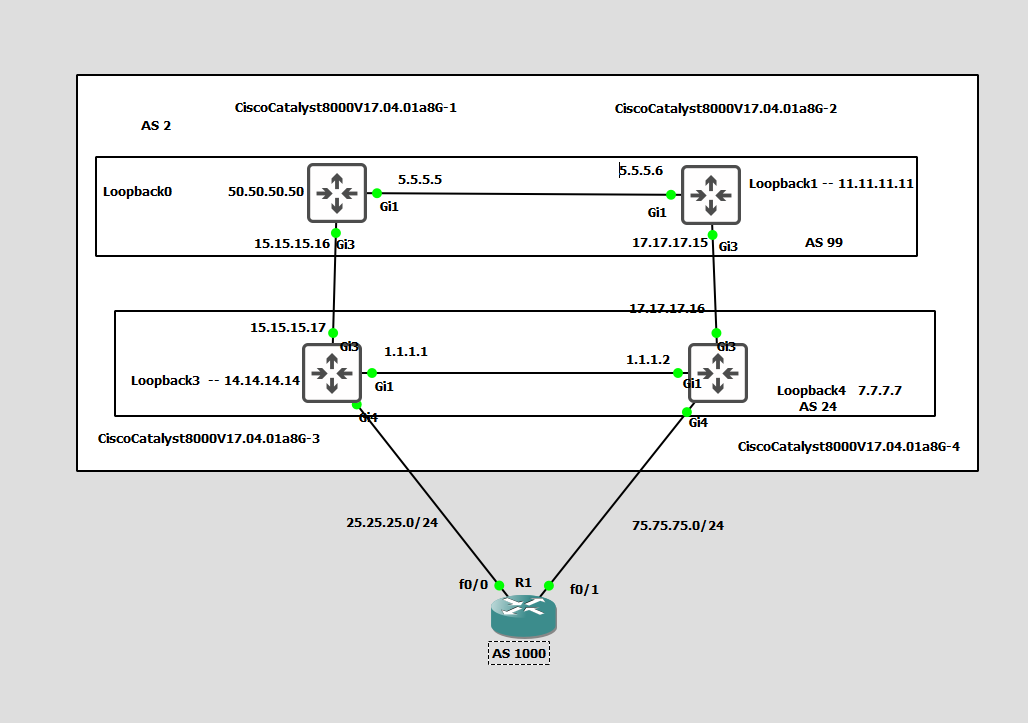
CAT 3 and CAT 4 are only advertising the 25.25.25.0/24 and 75.75.75.0/24 networks to which they are directly connected, so there are no networks beyond those, advertised by these two devices.
Check to see what other networks are being advertised by CAT1 and CAT2 to see what exists within the BGP tables of all of the routers in AS 2.
Remember that BGP will only advertise networks indicated with the network command or networks that are redistributed. More about this can be found in the following lesson:
Remember also that prerequisites to a prefix being advertised is that the prefix itself is found in the local routing table with the exact same subnet mask.
Let us know how you get along and if you need any additional help in your troubleshooting process.
I just had one small doubt considering the topology that is used.
We see that the route advertised by R1 appears on R5 with two paths available. One from the confed-Internal and one is from confed-External, as mentioned if BGP doest not distinguish between confed and normal internal/external peerings for best path selection, then why R5 selects route to R1’s loopback through R3 (internal bgp) instead of through R4(external bgp) as we usually prefer external bgp routes to internal.
When we apply confederations, as far as BGP is concerned, you are using iBGP regardless of whether you are communicating with a router in your own sub-AS or a different sub-AS, as long as the routers are both in the same normal AS. As Rene says:
In the BGP best path selection algorithm, there is no distinction between confederation external or internal.
So from the point of view of R5, the peerings with R3 and R4 are considered the same, that is, both use iBGP because they’re in the same normal AS of 2.
So the only thing that will make R5 choose one peer over the other is the lowest router ID which is that of R3.
In the real world, what’s more commonly used to avoid the iBGP full-mesh requirement? Route Reflectors or Confederations? Or does it depend? Because I find RRs way easier to understand and also configure. Confederations also require some more planning, correct?
You are indeed correct that both RRs and confederations are used to manage large ASes where a conventional iBGP full-mesh would be too cumbersome to deploy. And it is also true that in general, RRs are simpler to deploy than confederations. So when should we use one or the other? Here are some guidelines that will help to make such a decision:
RRs are generally preferred in networks where simplicity of configuration and maintenance are paramount. The primary use case for RRs is within a single, large AS. One drawback of using RRs is the fact that you have a single point of failure (the RR) but that can be remedied by applying a redundant RR.
Confederations, on the other hand, are typically used in complex network environments where the organization has a need for extensive control over routing policy and wants to manage it in a hierarchical way. They are particularly useful for large, complex networks divided into many different segments or subnetworks. Essentially we are saying that confederations scale better than RRs simply because you are breaking your AS into smaller ASes.
Additionally, confederations give you a higher degree of control over routing policies between different parts of your AS, assuming your AS can be organized in such a way that it is effectively divided into sub-ASes with a clear hierarchy. Of course, as you mentioned, there is a tradeoff. Confederations are more complex, but they give you more control.
So in a nutshell, while both techniques can be used to simplify iBGP configurations, RRs are typically easier to implement and manage, making them suitable for simpler networks. Confederations, while more complex, offer more fine-grained control and flexibility, making them more suitable for larger or more complex networks.
It’s probably a nitpicky detail but there’s one more thing that I would like to know. I know that routers in a Sub-AS prepend a path attribute called “AS_CONFED_SEQ” which is an organized list of Sub-ASes the traffic traversed through to the AS Path field
However, as you can see, these ASNs are also prepended to the AS Path field itself. Any idea why?
From what I’ve read, they are not used when determining the shortest path to any destinations and there’s already a path attribute called AS_CONFED_SEQ which is an ordered list of confederation ASNs the UPDATE packet traversed through. So can’t the router just use AS_CONFED_SEQ to see which Sub-ASes did the traffic pass through? Why’s there also the need to prepend it to the AS Path field itself?
It’s interesting to look at the inner workings of BGP and how the format of its updates changes depending on whether or not confederations are used. RFC 3065 explains in detail the use of the AS_CONFED_SEQUENCE attribute, and there are specific modification rules that are used to determine how and when it is used.
Now that takes care of how the mechanism works. The question now is why is it done this way? Well, first of all, we have to keep in mind that the AS_PATH itself has no notion of sub-ASes. The ASes in the path are those that have been traversed, and it makes no distinction between whether they are normal ASes or sub-ASes. For this reason, we need another attribute (the AS_CONFED_SEQUENCE attribute) to identify which of those ASes are sub-ASes. These must be identified so that they are dealt with correctly under all circumstances, as described in the RFC. Does that make sense?
I saw that the lesson states that the AS_CONFED_SET is created as a path attriubute. I was using Wireshark to check this anc could not find it. It seems this is now not recommended according to the below: https://datatracker.ietf.org/doc/draft-ietf-idr-deprecate-as-set-confed-set/ so I am guessing the routers I am using do not use this attribute.
You’re correct. The AS_CONFED_SET is indeed a path attribute that was previously utilized. However, as per the draft you linked, it is now recommended to deprecate the use of AS_SET and AS_CONFED_SET in BGP. This is due to the fact that these attributes can create routing loops if not managed correctly.
This draft is quite new, not even a half year old at the time of the writing of this post. Even so, it is possible the routers you’re using have updated their software to align with this recommendation, hence why you’re not seeing the AS_CONFED_SET attribute in Wireshark. What routers and IOS are you using?
There are two things which i would like to highlight
you might need to change the statement as “There’s one more thing we have to do…since the next hop doesn’t change with iBGP”
Configuration example
There’s one more thing we have to do…since the next hop doesn’t change with BGP, our routers will not know how to reach 192.168.12.1 (R1). I’ll fix this by advertising the 192.168.12.0 /24 network in BGP:
We normally do not advertise external links into BGP , in the above configuration example you have advertised 192.168.12.0/24 into bgp , instead we can change the next hop behaviour with the command “next-hop-self” . cant we just configure R2 as below
I will let Rene know to reword this so that it is more accurate. The next hop does not change when R2 shares its route to the destination with its iBGP peers.
Best practice is indeed to use the next-hop-self command in this case. However, for the purposes of this lesson, Rene has chosen to use the network command to advertise this network for simplicity and quickness. If he introduced the next-hop-self feature now, he would have to explain it, but the focus of the lesson is on the explanation of confederations. There is another lesson that deals with the next-hop-self feature.
Thanks for the suggestion. Like @lagapidis said, I used the network command to keep it simple. I added a note with a link to the BGP next hop self lesson though.