Hello Galen
This is actually expected behavior.
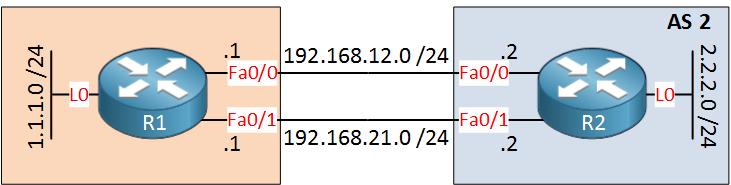
When you configure a BGP neighbor using a loopback address (for example 2.2.2.2), the router will attempt to establish a TCP session to that address. However, unless you configure update-source, the router will use the IP address of the outgoing interface as the source of the TCP session.
So with these configs:
R1:
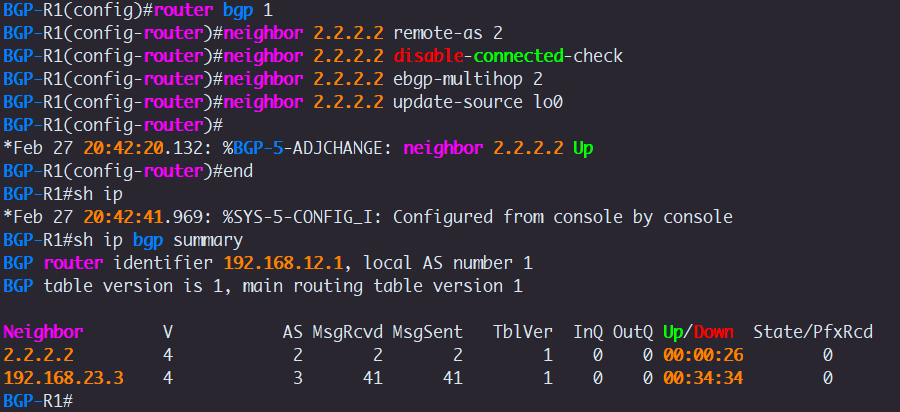
neighbor 2.2.2.2 remote-as 2
neighbor 2.2.2.2 disable-connected-check
neighbor 2.2.2.2 ebgp-multihop 2
R2:
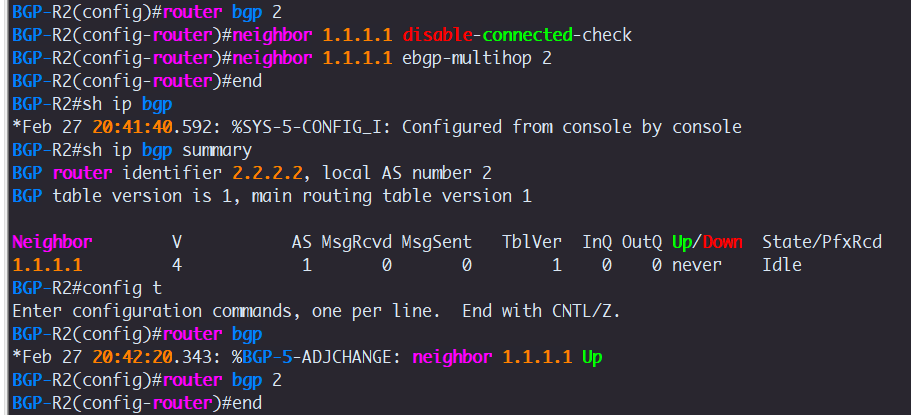
neighbor 1.1.1.1 remote-as 1
neighbor 1.1.1.1 disable-connected-check
neighbor 1.1.1.1 ebgp-multihop 2
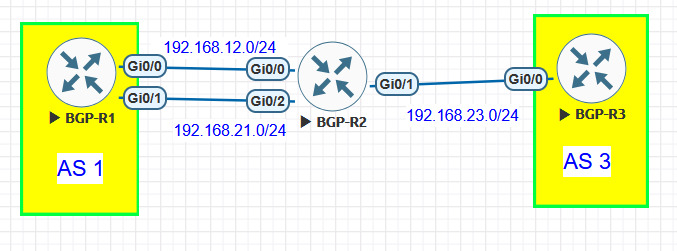
…both R1 and R2 will attempt to establish a TCP session between the local exit interface IP and the remote loopback IP, and based on your diagram:
- R1 will use a source IP of 192.168.12.1 or 192.168.21.1 and a destination IP of 2.2.2.2
- R2 will use a source IP of 192.168.12.2 or 192.168.21.2 and a destination IP of 1.1.1.1
This causes the session to fail because BGP performs a strict neighbor check:
- R2 expects a TCP connection from 1.1.1.1
- But it receives a connection from 192.168.12.1
- Therefore, it rejects the session (neighbor mismatch)
The same thing happens on R1 as well.
Now if you issue this command, neighbor 2.2.2.2 update-source lo0 on R1, the source IP of the TCP SYN packets becomes 1.1.1.1 (the loopback).
At that point, R2 receives a TCP connection whose source matches its configured neighbor (1.1.1.1), so it accepts the session and the BGP adjacency comes up immediately.
This is why you only need the command on one side for the session to form, as long as at least one router initiates a connection with the correct source IP, the other side can accept it.
Does this work in production?
Yes, but in production networks it is strongly recommended to configure update-source loopback on both routers when peering via loopbacks. This ensures:
- Stable peering independent of physical link failures
- Predictable session sourcing
- Clean and symmetric configuration
- Proper session re-establishment from either side
Running it asymmetrically may work, but it is not considered best practice and can lead to troubleshooting confusion later. Make sense?
I hope this has been helpful!
Laz