Dear Rene,
Could you please clear about the MP-BGP ? Is it newer version of BGP ?? I am little bit confused about MP-BGP .
br/zaman
Dear Rene,
Could you please clear about the MP-BGP ? Is it newer version of BGP ?? I am little bit confused about MP-BGP .
br/zaman
Zaman,
MP-BGP (which is also called MBGP) isn’t a new a version in that it still is BGP version 4. MBGP simply means that it has additional extensions (called multiprotocol extensions) that allow it to carry information about address families other than IPv4. Examples of these additional address families include IPv6 Unicast, VPNV4, VPNV6, IPv6 Multicast, and IPv4 Multicast.
19 posts were merged into an existing topic: Multiprotocol BGP (MP-BGP) Configuration
had the same question. thank you. so by default bgp ipv4 unicast is only allowed and activate uses the ipv4 multicast 244.0.0.2 address. which will now allot that by activate command. am I right?
BGP by default, only has the IPv4 unicast family activated so you can advertise IPv4 unicast prefixes, that’s it. By enabling other address families, you can advertise things like multicast routes or VPN routes. BGP doesn’t use multicast addresses itself, it will always use a TCP session between two neighbors, that’s it.
thank you. i appreciate your help
Hi Rene - why does MP-BGP and MPLS always seem to go hand in hand? Do you need MPLS to run MP-BGP? Are they mutually exclusive?
Hello Gareth
The major benefit of MP-BGP is the fact that it can route IPv4 and IPv6 unicast and multicast addresses. However, it’s connection to MPLS is primarily, and almost exclusively related to the use of MPLS VPN.
An MPLS VPN consists of a set of sites that are interconnected by means of an MPLS provider core network. At each site, there are one or more customer edge (CE) devices, which attach to one or more provider edge (PE) devices. PEs use the MP-BGP to dynamically communicate with each other. It is an integral part of the MPLS VPN architecture. MP-BGP is actually REQUIRED on the network to allow it to function.
I hope this has been helpful!
Laz
diff AS so the route-map to change the NEXTHOP has to be applied outbound not inbound i hv tested it
Hi,
I had worked this lab in IPV4 before but when I got to this I was confused a bit.
You had the following:
I see that you go into the address-family ipv4 and I am good there but then I see you do the no activate on the ipv6. Here is where I am confused; have yet to find granular details and also checking my kindle book for info as well:
Doyle, Jeff. Routing TCP/IP, Volume II: CCIE Professional Development: CCIE Professional Development: 2 (Kindle Location 15220). Pearson Education. Kindle Edition.
The Kindle books has this in bold at the top:
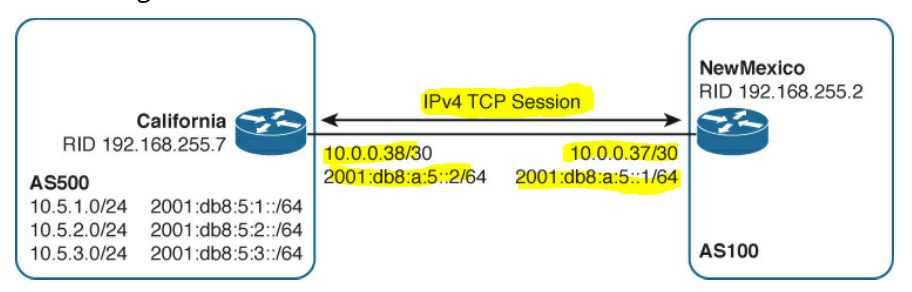
IPv4 and IPv6 Prefixes over an IPv4 TCP Session
From the title it seems to suggest that IPV4 and/or IPV6 create TCP sessions and you can send IPV6 prefixes as well as IPV4 prefixes over the session regardless of type.
Think of these as just prefixes in essence objects if you will that are being passed over TCP (transport layer) session.
below is a picture I found to help visually explain this from my kindle book as well.
Let me know if this is correct thinking.
I started thinking… IPV4 is 32 bytes and IPV6 is 128bytes… now I know we are talking about layer 4 which is the transport layer so I guess you just stick the 128byte into the transport layer TCP but then wouldn’t it be called TCP/IPV6 instead of TCP/IP?
I actually have never thought about IPV6 in regards to the OSI model…
Went back and read all the forums post a second time and now after I am on the right track I see that a few others was talking about this as well. Not sure why I didn’t pick it up the first time.
Hello Brian,
With MP-BGP, there’s basically two things:
It’s best to see the stuff that we advertise as “objects” or something. Once a session is established, you can advertise whatever you want. It’s possible to have an IPv4 neighbor adjacency and advertise IPv6 prefixes or the other way around, an IPv6 neighbor adjacency and advertise IPv4 prefixes. It also makes sense…it’s better to have a single neighbor adjacency and advertise anything you need through that single session.
Technically, when you use IPv6 you can call it TCP/IPv6.
Rene
Hi Rene
i receive configuration error
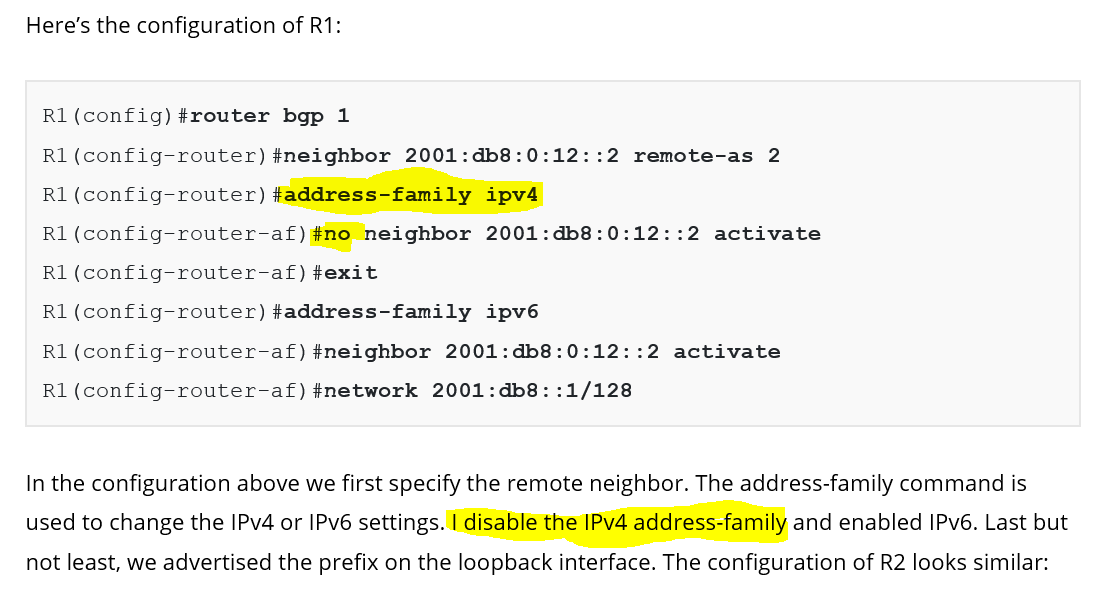
R1(config-router)#address-family ipv4
R1(config-router-af)#no neighbor 2001:db8:0:12::2 activate
% Specify remote-as or peer-group commands first
R1(config-router-af)#
Hi Rene
i solved it
R1(config-router-af)#no neighbor 2001:db8:0:12::2 remote-as 2 activate
thank you
nice to knit you
I came here looking for this information.
It doesn’t make sense to set the route-map for “in” bound traffic…
Can someone clarify if the keyword “out” was supposed to be used instead?
It makes sense to create the route-map that sets the IPv6 next-hop address for outbound traffic destined for 192.168.12.2?
Please explain Rene!!
Hi Brandon,
Both options are possible. This sentence is confusing though:
Both routers will now advertise their IPv6 address as the next hop for all prefixes that are advertised.
This isn’t correct since we fix the issue inbound, the routers still have no next hop to advertise. I just changed this sentence.
Let me explain this in detail. We can see what R1 advertises to R2:
R1#show ip bgp ipv6 unicast neighbors 192.168.12.2 advertised-routes
BGP table version is 4, local router ID is 192.168.12.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
t secondary path,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::1/128 :: 0 32768 i
Total number of prefixes 1
When R2 receives this prefix, there is no valid next hop, so it shows up like this:
* 2001:DB8::1/128 ::FFFF:192.168.12.1To fix this, you have two options:
This also applies the other way around for prefixes that R2 advertises to R1.
Both options work. Here’s an example of an outbound route-map:
R1(config)#route-map IPV6_MY_NEXT_HOP permit 10
R1(config-route-map)#set ipv6 next-hop 2001:DB8:0:12::1
R1(config)#router bgp 1
R1(config-router)#address-family ipv6
R1(config-router-af)#no neighbor 192.168.12.2 route-map IPV6_NEXT_HOP in
R1(config-router-af)#neighbor 192.168.12.2 route-map IPV6_MY_NEXT_HOP outDelete the inbound route-map on R2:
R2(config)#router bgp 2
R2(config-router)#address-family ipv6
R2(config-router-af)#no neighbor 192.168.12.1 route-map IPV6_NEXT_HOP inReset BGP to speed things up:
R1#clear ip bgp *Check R2:
R2#show ip bgp ipv6 unicast
BGP table version is 3, local router ID is 192.168.12.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
t secondary path,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::1/128 2001:DB8:0:12::1
0 0 1 i
*> 2001:DB8::2/128 :: 0 32768 iR2 has the correct next hop but this time we fixed it from the source (R1).
Both options work, I agree it might be “cleaner” to fix it outbound on R1 but both are valid options.
I hope this helps!
Rene
Thanks for replying back.
I am probably thinking too hard about this, but if the next-hop IPv6 address is changed on R1 for ingress traffic, how does R2 learn that information so it can add the new next-hop address?
Hi Brandon,
With the inbound route-map, the only thing we change here is the next hop we use for the prefix so we know how to route. Let me explain:
Before the inbound route-map:
After the inbound route-map:
With the outbound route-map, it’s different. In that case, R1 adds the correct next hop to the prefix and advertises it to R2. R2 then learns the prefix with the correct next hop that it can use.
Does that make sense?
Rene
Yes it makes sense. Thank you!
Hi
I which case the iv4 bgp peering to advertise ipv6 prefixes would be valid or useful?
Isn´t better to just use ipv6 bgp peering and problem solved?