Why did u activate the Ipv4 neighbor in IPv6 address family ??. Will it impact anything ??
i think the best configuration is , configure all the Ipv4 and Ipv6 neighbor globally and activate them in their respective address-family ??
Why did u activate the Ipv4 neighbor in IPv6 address family ??. Will it impact anything ??
i think the best configuration is , configure all the Ipv4 and Ipv6 neighbor globally and activate them in their respective address-family ??
Hello Narad
The neighbor activate command is used to activate a neighbor. By default, the exchange of addresses with BGP neighbors is enabled for IPv4 address family by default. It is disabled by default for all other address families, such as IPv6. So in this particular case, the command is necessary. Since IPv4 is being used for a neighbor peering to exchange IPv6 addresses, and since this is all configured within the IPv6 address family mode, this command must be applied. More information about it can be found here:
Now It is obviously cleaner and more consistent to create an IPv6 adjacency with IPv6 prefixes. However, this is not always possible. What if you have a connection between BGP peers that is using IPv4? Such a configuration is not applied as best practice, but out of necessity.
I hope this has been helpful!
Laz
Hi,
I have been configuring Ipv4 & Ipv6 address family, so do we need to use
no neighbor IPv6 activate and no neighbor IPv6 no shutdown in ipv4 address family and then neighbor ipv6 activate & attaching route map in Ipv6 address family
or both commands of no neighbor activate & shutdown can be used in IPv6 address family also instead of in Ipv4 address family
Hello Nitin
Whenever you issue the neighbor command, the default address-family used is IPv4. For this reason, you must explicitly deactivate the neighbor used within the ipv4 address-family configuration mode and activate it on the ipv6 address-family mode.
It must be done in this way, because you cannot deactivate the IPv4 neighborship from the IPv6 configuration mode.
I’m not sure if I’ve fully answered your question, but if not, feel free to clarify and let us know…
I hope this has been helpful!
Laz
Hi Rene,
Please help explain when is the command ‘address-family ipv6 multicast’ used? Can it be use to advertise routes into IPv6 MP-BGP?
router bgp 65000
no bgp default ipv4-unicast
address-family ipv6 multicast
network 2001:DB8::/64
Hello Kenneth
Under the BGP configuration, when you configure an address family, you are choosing to configure the BGP session for a particular type of traffic. If you don’t use the address-family command, and you configure BGP directly, then you are actually configuring the IPv4 address-family, since this is the default.
By issuing the address-family ipv6 multicast command, you are placing the router in IPv6 address family configuration mode. Specifically, you are indicating to the router that you want to create IPv6 multicast routing sessions.
This particular command is used when you want BGP to advertise IPv6 multicast address prefixes.
For more information, take a look at this Cisco command reference that further explains the use of this command:
I hope this has been helpful!
Laz
Any used cases or labs for using address-family ipv6 multicast and also elaborate more on its usage with RPF.
Hello Kenneth
The address-family ipv6 multicast command is used when you want to route multicast traffic between ASes. Remember, multicast is not supported on the public Internet, for IPv4 or IPv6, so such a configuration must be employed within a private enterprise network that may have several interconnected BGP ASes.
So let’s say you have a large enterprise network with multiple sites that are interconnected via some VPN/tunneling service that supports multicast. Your network is large enough to contain multiple private BGP ASes. Let’s also say that you are running multicast on this network. How will you route multicast traffic between ASes? Using MP-BGP with the appropriate command.
For more info on this feature and how it can be applied, take a look at this Cisco documentation:
Concerning RPF lookup, the multicast configuration (for both IPv6 and IPv4) simply allows BGP to perform the RPF lookup as needed to eliminate loops in much the same way that it is described here:
I was unable to find a lab or an example for the IPv6 multicast BGP address family, but I was able to find some examples of the application of ipv4 multicast address-family at the following links:
The following is from a Cisco Live presentation, and on slide 59 you will see an application for use with MPLS.
https://www.ciscolive.com/c/dam/r/ciscolive/us/docs/2018/pdf/BRKIPM-3017.pdf
I hope this has been helpful!
Laz
I think we can also use mpbgp without mpls
Using gre or vxlan should be ok, an i right?
Which overlay we can use instead of mpls?
Sometimes u need like this solution if you’re using switch from different vendor that doesn’t support mpls like dell for example in their new os which is os10.
@ReneMolenaar
Hello Ali
Yes, MP-BGP is not exclusively implemented with MPLS. It can indeed be used with VXLAN and EVPN as well. Remember its primary purpose is to support unicast and multicast IPv4 and IPv6. It is well suited to carry MPLS VPN labels as well.
I hope this has been helpful!
Laz
Hello, everyone!
I have a few questions about this MP-BGP topic.
First of all, what’s up with these unicast/multicast address families? Unicast makes sense but what exactly is Multicast used for? Would the BGP session behave any differently if I configured the IPv4/IPv6 address family as multicast instead of unicast?
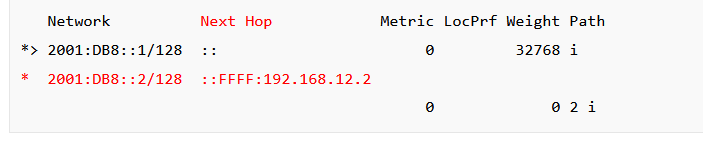
The next question is, what exactly is this Next-Hop supposed to represent?
I can see the IPv4 next-hop (R2) but what’s up with the ::FFFF before it? What does it mean? Is it really necessary to configure an IPv6 Next-Hop if there already is an IPv4 one?
And the last question. So we can basically carry IPv4 prefix information within an IPv6 BGP session and vice-versa. However, it’s for the best to have a separate session for both address families, correct?
Also, isn’t it better to set the link-local address as the next hop instead of the GUA?
I am enclosing my BGP studies with this topic. Thank you very much for all these excellent articles, videos, and help on the Community Forum! ![]()
David
Hello David
In situations where you want to run multicast services across multiple ASes, you can use MP-BGP to ensure that multicast routing information is propagated from AS to AS. PIM is the protocol used inside an AS for routing of multicast traffic. It establishes multicast distribution trees and propagates multicast traffic along these trees within the AS. MP-BGP, on the other hand, is an extension of BGP that supports multicast. It’s used to carry multicast routing information between different ASes.
When you see an IPv6 address starting with ::FFFF: followed by an IPv4 address, this is an example of an IPv4-mapped IPv6 address. This special type of address is used to represent an IPv4 address in an IPv6 format. These mapped addresses are used in a dual-stack environment where both IPv4 and IPv6 are deployed. IPv4-mapped IPv6 addresses provide a mechanism for IPv6 applications to communicate with IPv4 applications and vice versa.
When exchanging IPv6 prefixes over an IPv4 peering link, the next hop address for IPv6 routes will be indicated using an IPv4-mapped IPv6 address. This is because the BGP session itself is established using IPv4, so the next hop for IPv6 routes must be represented in a form that’s compatible with the underlying IPv4 transport, hence the use of IPv4-mapped IPv6 addresses. For Cisco devices this should work fine, however, it is not ideal, and this is the reason Rene added the IPv6 addresses on the interfaces.
It is preferable to do so yes, primarily to keep things organized and manageable from an administrative point of view. It is much easier to understand and to troubleshoot such a configuration.
Either global unicast or link-local addresses can be used for this purpose. However, it is generally preferable to use the global unicast, and here are some reasons why:
These are just some thoughts. TEchnically, you can use the link-local addresses as long as your BGP peer is directly connected, however, generally, it is preferrable to use the global unicast.
Great to hear that your studies of BGP are complete here, and glad to hear that the site and the forum have all been helpful to you! Looking forward to seeing you in other areas of the forum as well!
I hope this has been helpful!
Laz
HI Rene,
I assume that using IPV4 for neighbours and exchanging ipv6 routes is just a hold out mechanism while IPV4 is still the dominant scheme. I assume that once IPV6 becomes standard, this won’t be needed, as it does seem a bit redundant, if you have to configure an IPv6 address anyway on the outgoing interface.
Thanks.
Hello Artur
Yes, ideally we would like to have IPv6 everywhere, however, as you correctly stated, there are situations where IPv4 is still around, and we need to be able to accommodate those situations. Make no mistake however, IPv4 is still going to be around for a long time. How long, no one knows, however, it will definitely be long enough to make learning such techniques worthwhile.
I hope this has been helpful!
Laz
i have question why we use this command neighbor 2001:db8:0:12::2 activate
why we use activate and i didn’t saw explain about this command in BGP Course ?
Hello Osamah
When configuring BGP neighbors, the address family that is used by default is IPv4. So when you configure neighbors, you do it simply like this:
R1(config)#router bgp 1
R1(config-router)#neighbor 192.168.10.10 remote-as 2
That automatically activates the neighbor peering using IPv4. Now if you want to create a peering using another protocol, such as IPv6, that means that you must first issue the neighbor command like this:
R1(config)#router bgp 1
R1(config-router)#neighbor 2001:db8:0:12::2 remote-as 2
At this point, because IPv6 does not activate the neighbor by default, you must issue the neighbor activate command. This command is issued within the address family configuration mode. So to complete the above IPv6 peering configuration, you must continue like so:
R1(config-router)#address-family ipv6
R1(config-router-af)#neighbor 2001:db8:0:12::2 activate
So when you’re not using IPv4 peerings, the neighbor remote-as command configures the neighbor peering, but the neighbor activate command activates it.
You can disable the automatic activation of IPv4 neighbors by issuing the no neighbor activate command. That way, IPv4 peerings will behave the same as peerings using other protocols, such as IPv6.
I hope this has been helpful!
Laz
R2#show ip bgp ipv6 unicast
BGP table version is 2, local router ID is 192.168.12.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* 2001:DB8::1/128 2001:DB8:0:12::1
0 0 1 i
*> 2001:DB8::2/128 :: 0 32768 i
hi rené,
the announced prefix is not installed in my BGP table even though the configuration is well done what could be the problem
Hello Christian
Thanks for your post! I’m not quite sure where the specific problem is. I see that you have the same output as that in the lesson. Which advertised prefix does not appear in the BGP table? Can you clarify so we can help you further? Looking forward to your response!
I hope this has been helpful!
Laz
Hi,
MP-BGP with IPv4 adjacency & IPv6 prefixes
for the above part, is it possible to have adjacency over IPv6 but share IPV4 prefixes?
The disadvantage of it would be setting next hop for IPv4 by ourselves but advantage would be the same that we can advertise both IPv4 and IPv6 prefixes?
Thanks
Hello Görgen
Yes, it is possible to create an IPv6 BGP peering and advertise IPv4 prefixes. And you’re right, one of the main difficulties in doing so is the increased complexity involved with IPv4 next hops. IPv4 routes may reference an unreachable IPv4 next-hop if the underlay is IPv6-only. This is dealt with using RFC 5549. This RFC defines a standard method that enables BGP to advertise IPv4 routes with an IPv6 next-hop, eliminating the requirement for IPv4 addresses in the control plane between BGP peers.
This arrangement is commonly employed for networks that are in the process of transitioning from IPv4 to IPv6.
I hope this has been helpful!
Laz