Hello Dominique
The answer is yes, even for one fail, the action is taken immediately. It is the threshold that is taken into account as far as if the action is to take place. The timeout is there so that a device will not be waiting for multiple “unresponsive” probes as time goes on, resulting in the use of resources.
Now this brings up a good question. What happens if the SLA is triggered over and over due to a flapping state. This would mean that actions would be taken continuously resulting in degradation in service. There is an additional parameter that can be configured, in object tracking which is the delay. You can delay the action taking place for several seconds. You can also delay the action that is taken upon restoration of the SLA state. You can find out more about this command on page 12 of the following documentation:
As for your second question, when Rene shutdown the port on the ISP, we get the following:
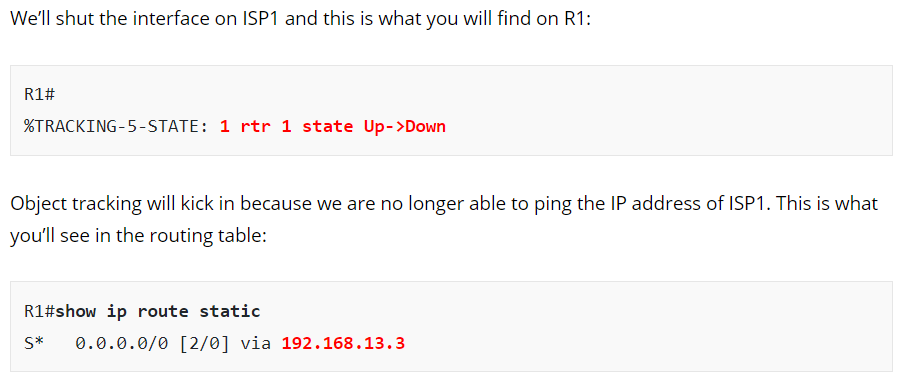
Can you specify where in the lesson you see that the interface on R1 remains up?
I hope this has been helpful!
Laz