Split horizon helps to mitigate loops in networks where you may have connections like R1 — R2 — R3 — R4. If R4 loses access to one of its directly connected networks, and R3 learns about this, it will remove it from its routing table. But then it may learn about that route from R2 which has it in it’s routing table (learned from R3) and think that R2 has an alternative route to it, causing problems and chaos.
In Frame Relay networks, you never have such a topology (and if you do, you should revise your network design) so you don’t have the same danger of learning about a dropped route from another router in the same way. In Frame Relay, you can safely disable split horizon as the route poison function is enough to ensure that no incorrect routing information will be shared.
A) Why rip works at application layer and what was the reason behind that both source port and destination port use 520 as i think they will choose random port .
B) Could you please explain about the triggered update in both Version 1 and Version 2 . Is it same in both or they perform different to each other ,
Look please clarify it in triggered update is they advertize about newly routes or down routes to neighbour route only or exchange their complete routing table every 30 Second and it is same in both version .
Rgds
Chahal
RIP is an application layer protocol because its functionality takes place at the application layer. As such, it uses a transport layer protocol, namely UDP, to transmit its various messages in order to propagate routes to all RIP routers. Typically, most protocols will choose to use a random source port, and a specific destination port for their transport layer communications. However, as you say, and according to RFC2453, RIP uses port 520 as both its source and destination port. All of this is simply due to the design of the protocol itself.
The triggered update in v1 and v2 function the same way. You can confirm this by looking at the related section in RFC1058 (v1) and RFC2453 (v2).
Triggered updates work as follows, according to the RFC:
To get triggered updates, we simply add a rule that whenever a router changes the metric for a route, it is required to send update messages almost immediately, even if it is not yet time for one of the regular update message.
RIP sends a message every 30 seconds and shares its complete routing table. The triggered updates are sent before the scheduled updates if a change is detected. This behaviour is the same for RIPv1 and RIPv2.
Hi Rene.
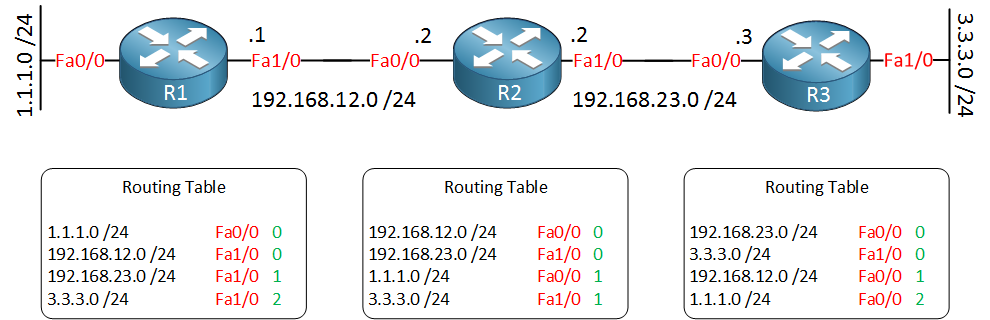
I have a question regarding the 2nd video in this section , the one that explains the problems with RIP. At around 1:42 of the video, I understood that that the R.3.3.3 network is learned from R2 on the F0/0 interface with a hop count of 1. Should this not be a hop count of 2? I was under the impression that as it already 1 hop away on R2, with R3 it will then be 2 hops away. Can you please clarify this? Thank you.
Yes, you are correct, that should indeed be a hop count of 2. This is reinforced in the 2nd image below the video that shows how R2 informs R3 of a route to 3.3.3.3 where the hop count is indeed 2.
I will let Rene know so that he can make any necessary changes…
im a little confused about route poison & poison reverse. Why it’s necessary a poison reverse ? taking by example de R1<->R2<->R3 of this lessson, when network 3.3.3.0/24 directly connected on R3 fails, R3 triggers an update with a route poison message with infinite metric (16), so R3 sets metric 16 for itself and announce the same to R2, R2 process it and set metric 16 for 3.3.3.0/24 and R2 sends it to R1, R1 process it and set metric 16. So 3.3.3.0/24 would be marked as unreachable in all routers.
is this statement right at this point ?
My doubt is about the necessity of poison reverse… i don’t know if i misunderstood this concept but in the lesson says poison reverse is a backward message to the originating router not forward traffic to the route that has failed… Why is necessary if in the 1st route poison originated by R3 it sets metric 16 for itself ?
And another doubt is when R2 & R1 detects 3.3.3.0/24 down and set metric 16 (due the route poison received from R3) while these timers are counting, whether it’s R1 or R2 wny would they receive a better metric from other rip neigh ? i guess the poison route propagates to all rip routers, and if there is a possible better metric , which metric , 16 or the original one ?
EDIT : I’ve asked bard.google (AI) about this but im not sure about its accuracy
The AI reply :
That is correct. Route poisoning marks a route as unreachable by setting the metric to infinity. Poison reverse indicates to not advertise a route by advertising the route to neighbors with a metric of infinity.
Route poisoning is used to quickly remove invalid routes from routing tables. Poison reverse is used to prevent routing loops from forming. By using both route poisoning and poison reverse, routers can help to ensure that their routing tables are accurate and that routing loops do not occur.
Here is a table summarizing the differences between route poisoning and poison reverse:
Feature
Route Poisoning
Poison Reverse
Purpose
To mark a route as unreachable
To prevent routing loops
When used
When a router learns about a route that is unreachable
When a router learns about a route from a neighbor that is not the next hop
How it works
Sets the metric of the route to infinity
Advertises the route to neighbors with a metric of infinity
I hope this helps! Let me know if you have any other questions.
I understand how route poisoning and poison reverse can be a bit confuing, especially because of the similar terminologies. Let me try to clarify.
First of all, you must keep in mind that in the context of RIP, poison reverse is not a process that is used exclusively in conjuction with route poisoning. According to the RIPv2 RFC 2453, RIP uses what is called “split horizon with poison reverse.” As stated in the RFC:
The “simple split horizon” scheme omits routes learned from one neighbor in updates sent to that neighbor. “Split horizon with poisoned reverse” includes such routes in updates, but sets their metrics to infinity.
And…
In general, split horizon with poisoned reverse is safer than simple split horizon. If two routers have routes pointing at each other, advertising reverse routes with a metric of 16 will break the loop immediately. If the reverse routes are simply not advertised, the erroneous routes will have to be eliminated by waiting for a timeout.
So poison reverse makes the process much more efficient.
Keep in mind that poison reverse is a mechanism that happens with any type of update that may be received, and not just with a triggered update, as in the lesson. Does that make sense?
Im reviewing EIGRP topic but im still struggling to have a good understanding only about this subtopic “route poisoning” and “poison reverse”. By your explanation, now im understand , both route poisoning and poison reverse are not strictly linked each other.
But im still confussed about the detalied process .
Example :
R1 <----> R2 <---->R3 -|(network 3.3.3.0/24)
Suddenly, R3 3.3.3.0/24 goes down , the 1st msg will be a “route poisoning” msg setting an infinity metric (16) locally on R3 and also send this update towards R2 who receives this route poisoning msg and also set infinity metric (16) and propagates it towards R1.
Now, the poison reverse msg, for my understanding implies an exception to the split horizon rule (such as you’ve explained in your previous post) that implies a R2 update with an infinite metric (16) towards R3 for a route that R2 previously learnt from R3… isn’t it ?
If am right about the above, it brings me a question… Why is it a neccesity for R3 receive this “split horizon with poisoned reverse” if R3 will never have in its RIP database the 3.3.3.0/24 pointing to R2 ?
UPDATE : I’ve re-read the lesson. What i’ve said in my last statement “R3 will never have in its RIP database the 3.3.3.0/24 pointing to R2 ?” would be in incorrect because when 3.3.3.0/24 goes down on R3 it onlytriggers a route poisoning to with infinity metric to R2 but ONLY for 3.3.3.0/24 pointing to R3 . So, now R2 could update R3 sending a erroneous metric telling it 3.3.3.0/24 could be reached towards me (R2) but instead R2 uses split horizon with poison reverse, therefore sending and update to R3 for the 3.3.3.0/24 pointing to R2 but with an infinity metric…
Please, give some feedback if im right now or not and i apologize for overcomplicating it.
In your UPDATE, you have correctly understood the reasoning behind the use of split horizon with poison reverse. No need to apologize, as this is indeed a complicated process to get your head around.
There is a sentence in this lesson which is “I can reach 3.3.3.0 /24 by going to R3 and my hop count used to be 1. I’m receiving a routing table from R3 now, and it now says that the hop count is 2…I need to update myself to include this change”.
In the lesson 3.3.3.3 network is going down and R3 updating its routing table for this entry as down. But afterwards its metric suddenly become 2. How?
after 3.3.3.3 going down R2 would advertise its routing table which includes 3.3.3.3 route as with 1 metric. R3 would update its metric table for the route as 1.
in the las picture R2 and R3 would have 3.3.3.3 route with 1 metric. I didnt understand how 3.3.3.3 metric became 3 in R3 routing table.
To me I think even if R2 and R3 update themselves , the metric would stay same as they both have metric 1.
As you correctly stated, R3 loses connectivity to its directly connected 3.3.3.0/24 network. What happens next?
Notice the routing table of R2. R2 has a route to 3.3.3.0/24 with a hop count of 1. R2 will send an update to R3 saying “I have a route to 3.3.3.0/24 and my hop count is 1”.
That update will reach R3, and R3 will think “I have learned of an alternative route to the 3.3.3.0/24 network via R2. Its original metric is 1, so in order for me to reach it via R2, I will add one more hop for a metric of 2.”
Whenever a router advertises a route to a neighbor using RIP, it always adds 1 to the metric before putting it into its own routing table, simply because you’re one more hop away from the destination.
This however causes problems in the specific topology because R2 and R3 keep advertising themselves as the route to the 3.3.3.0/24 network when neither one really has a route to that network. This results in each update adding one more to the metric until the metric becomes 15 (i.e. infinite) and unreachable. Does that make sense?