Hi, getting confused with Scaling here. On Rene’s capture with Raspberry
1# On initial SYN, PC’s Windows Size advertised is 8192 and Scaling is 256. How are those being calculated? Are they OS dependent?
2# Same question for Rasp [29200/ WS= 64] on SYN/ACK packet. On packet itself scaling is 64 but calc window still remains 29200. How does the underlying algorithm would work as WS’d be multiplied for calculated window size?
Moreover, after handshake is completed, how come ACK turns to be 29?
![]()
![]()
I am taking about Rene’s other capture that is on comment section.
Hi Deep,
The window size depends on the OS. Windows uses a window size of 8192 bytes by default. Here’s a Microsoft document that shows some of the default values and how they can be changed in the registry:
The raspberry shows a window size of 29200 bytes. The highest value of the window size without scaling is 65535 bytes. You can ignore the scaling factor here since 29200 is less than 65535, we don’t need scaling for now.
I just checked the capture file again. The ACK you mention is packet #5. The ACK has a value of 29 since the packet #4 has a length of 28 bytes.
Hope this helps!
Rene
Hi Deepak,
I’ll create a capture for then when I write something on WRED. RED is a technique that randomly drops TCP traffic in order to slow down traffic, trying to prevent congestion. It’s a perfect way to see TCP and how it behaves with drops.
Rene
Hello Networklessons.com team
I would like to make a question regarding the topic. You said in the article that if a packet is dropped then the sender will send initially only one segment and after this will wait for the acknowledgement from the receiver for that one segment. So, the receiver sends a window size before the sender sends that one segment of let’s say 1460 bytes? Does the receiver know the MTU of the sender so that it can adjust the window size? Thank you in advance!
Best Regards
Markos
Hello Markos
First of all, the MTU is not involved in the process of windowing. The segment sizes are set based on the MTUs that are configured on the interfaces and the devices that are communicating.
So if there is congestion on the network, and a segment is lost, the receiver will respond by sending an acknowledgement that has a smaller window size, not necessarily a window size of one segment, but a window size much smaller than the current one. Once that is done, the segments will begin sending from the last successfully received acknowledgement. The window size will slowly increase once again.
I hope this has been helpful!
Laz
Hi Rene,
How do you configure window size in routers?
Thank you,
Shawn
Hello Shawn
It’s important to keep in mind where precisely window size scaling takes place. It is a mechanisms that is implemented using the TCP protocol, and is adjusted by the receiver of a TCP session. This means that if a router is transmitting information between two hosts that are currently in a TCP session, it is unable to interfere with any of the TCP parameters. Only the two devices involved in that particular TCP session are able to do so. The only way that a router could adjust the window size is if it itself is the destination of a TCP session.
It is also important to keep in mind that a router is primarily a layer 3 device and is involved in mechanisms that take place within the realm of the IP protocol. It rarely deals with layer four except in specialized services such as NAT and others.
I hope this has been helpful!
Laz
sir can u explain what is PDU
I got a question. Does delay in the RTT cause TCP slow start?
Hello Harshit
PDU is short for Protocol Data Unit. It is a generic term used to refer to a piece of data at various layers of the OSI model. For example, at the Transport Layer, if we’re using TCP, the PDU is called a Segment. If we’re using UDP, it is called a Datagram. At the Network Layer, it is called a Packet. At the Datalink Layer, it is called a Frame. We can use the term PDU to refer to these units in general. Here’s an example of the OSI model that includes the names of the PDUs at the various layers.
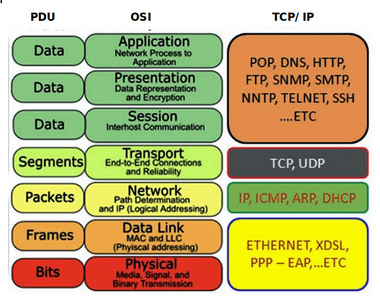
I hope this has been helpful!
Laz
1 Like
Hello Carlo
TCP slow start is caused when segments are dropped. A long round trip delay time (RTT) alone will not induce packet drops and will thus not directly cause TCP slow start. Now if the RTT is so long that TCP timeouts are reached and segments are considered lost or dropped, then yes, it can result in TCP slow start, but only because segments are considered dropped.
I hope this has been helpful!
Laz
1 Like
Thanks it has been helpully
1 Like
Hi together,
So am I right that the Window Size scaling factor is an option held in the options field ?
Best regards,
Marcel
Hello together,
In my book (CiscoPress / Kevin Wallace) RED is referred to as WRED (Weighted Random Early Detection) which is considered to be more correct of these two or is both ok ?
Best regards,
Marcel
Hello Marcel
Yes, you are correct, the Window Size scaling factor is indeed an option in the options field of the TCP header. You can find out more about it at the RFC1323 that describes it further.
RED and WRED are just two variations of the same type of mechanism used to perform the same function. In additino to WRED, there’s Adaptive RED, and Robust RED as well. Cisco specifically implements WRED on its switches by default, however, according to Cisco, you can also configure WRED to ignore IP precedence when making drop decisions, so that non-weighted plain RED behavior is achieved.
More on WRED and RED and how they are implemented in a Cisco device can be found here:
https://www.cisco.com/c/en/us/td/docs/ios/12_0s/feature/guide/fswfq26.html#wp1024722
I hope this has been helpful!
Laz
1 Like
Can you please explain TCP TAHOE vs RENO
Hello Raunak
Both TAHOE and RENO are both TCP congestion avoidance algorithms that are used, as the name suggests, to avoid congestion on TCP sessions between hosts. These algorithms kick in after “slow start” which is described in the the lesson of this thread. Specifically, they kick in when, after slow start begins, a loss event occurs. Once this happens, either TAHOE or RENO are employed.
The algorithms themselves are quite complex, and if you want to find out more about them, you can read about them, and how they are involved with slow start, here:
Now specifically, for the difference between the two (as stated in the link):
TAHOE - When a loss occurs, fast retransmit is sent, half of the current congestion window size (CWND) is saved as ssthresh and slow start begins again from its initial CWND. Once the CWND reaches ssthresh, TCP changes to congestion avoidance algorithm where each new ACK increases the CWND by MSS / CWND. This results in a linear increase of the CWND.
Conversely
RENO - A fast retransmit is sent, half of the current CWND is saved as ssthresh and as new CWND, thus skipping slow start and going directly to the congestion avoidance algorithm. The overall algorithm here is called fast recovery.
So the fundamental difference is that half the current CWND is saved as the new CWND so slow start is skipped, making the whole procedure faster. RENO is actually a successor to TAHOE in a way…
Remember however, that there are many more congestion avoidance algorithms that are used by various vendors, operating systems, and manufacturers. You can find out more about those by using your favorite search engine…
I hope this has been helpful!
Laz
You said above:
“When an interface has congestion then it’s possible that TCP packets are dropped”
In “Introduction to the OSI Model” where is presented protocol data units (PDU):
“Transport layer: Segments; For example, we talk about TCP segments.
Network layer: Packets; For example, we talk about IP packets here.
Data link layer: Frames; For example, we talk about Ethernet frames here.”
Question:
Why we are not talk about TCP segements?
Thanks for the lessons. They have many details, examples and are easy to understand.
Best Regards!
Hi Cismelaru,
Late reply but you are totally right, we have to keep our terminology in order. It’s either TCP segments or IP packets ![]() Fixed this!
Fixed this!
Rene