Hi Rene and staff,
i want to add another comment for the final solution. Perhaps it could help someone
"
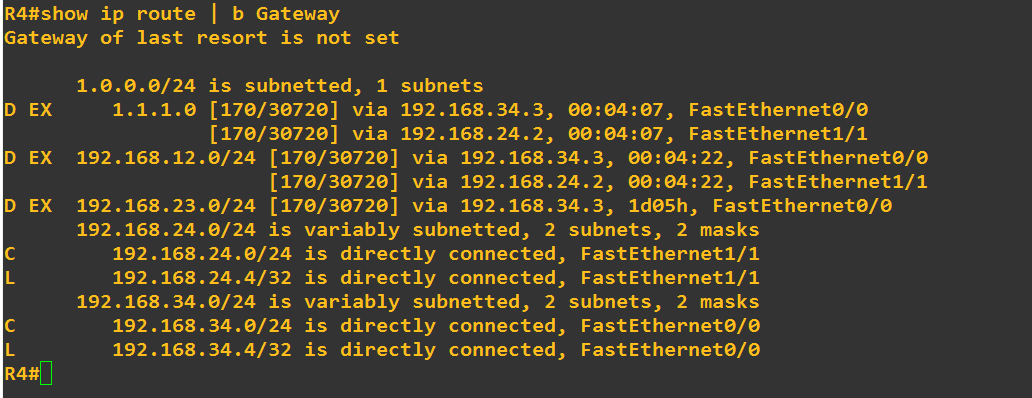
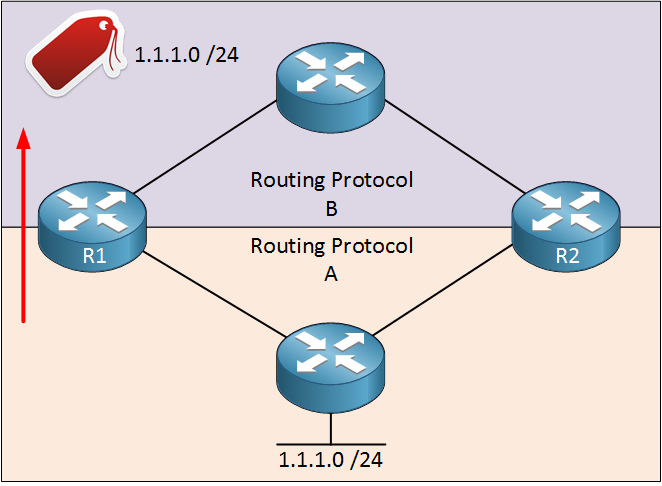
R4 will use the EIGRP external entry (AD 170) for 1.1.1.0 /24. R2 and R3 both redistribute 1.1.1.0 /24 into EIGRP, the route that R4 installs depends on the seed metric
"
In the lesson R2 redistribute RIP into EIGRP with BW=1000
And R3 redistribute OSPF into EIGRP with BW=1500
So in my opinion R4 will install the route via R3
I don’t know why so low values are used in the lesson with FastEthernet (?)
But in my GNS3 lab, i set R2 and R3 both to redistribute 1.1.1.0/24 into EIGRP with the same composite metrics (BW= 100 000, DL, etc..) So, with this topology and the same redistribution composite metrics and the same K-values, from the perspective of R4 there are two paths with the same metric, and EIGRP could load balance between these paths. Let’s find the R4’s RIB from my lab (in my lab the name of interfaces are not the same)
Regards
{kind=link}