This topic is to discuss the following lesson:
Hi Rene,
Thanks for your very nice article.
Please clarify ""If we use different hashing algorithm then the flow will be considered based on different parameter but same flow will use the same link,Not possible any load balance using different hashing algorithm , right ??? and if we use “ip load-sharing per-packet” at interface level then all packet will push across all available link . we can influence Load Balance , right ??
So In summary…
- Different hashing algorithm : Only flow will be consider based on different parameter like Src IP/dst IP/L4 Port etc.
- ip load-sharing per-packet at interface level : Per-Packet will be load balance across all link even though the packets are belong to same flow .
br//zaman
Hi Zaman,
What I mean by this is that for a single flow, the router always selects the same interface no matter the hash algorithm you use. The advantage of using a hash algorithm that uses more parameters is that you will have better load balancing since different flows will use different interfaces. For example, if you use a hashing algorithm that only includes source and destination IP address then it’s likely that the following flows will all get the same result and use the same outbound interface.
Here’s a quick example, let’s say we have these flows:
192.168.1.1 > 192.168.2.2
192.168.1.2 > 192.168.2.2
192.168.1.3 > 192.168.2.2
192.168.1.4 > 192.168.2.2
192.168.1.5 > 192.168.2.2
192.168.1.7 > 192.168.2.2
192.168.1.9 > 192.168.2.2
If we had two outgoing interfaces, it would be nice to see 4 flows on each interface so that we have some load sharing. However in reality, it’s likely that the flows get mapped like this:
INTERFACE 1:
192.168.1.1 > 192.168.2.2
192.168.1.3 > 192.168.2.2
192.168.1.5 > 192.168.2.2
192.168.1.7 > 192.168.2.2
192.168.1.9 > 192.168.2.2
INTERFACE 2:
192.168.1.2 > 192.168.2.2
192.168.1.4 > 192.168.2.2
In this case, interface 1 gets the most flows. By using a hashing algorithm with more parameters, the chance that each interface gets 50% of the flows increases. Still, this doesn’t consider how much traffic each flow has so it’s more like “flow” balancing than load balancing ![]()
Per packet load balancing does evenly share the load, even though the packets belong to the same flow yes.
1 Like
“Universal: each router generates a unique 32 bit universal ID that is used as a seed in the hashing algorithm next to the source/destination IP addresses. Since each router will have a unique universal ID, each router will have a different hashing result and a different interface will be selected for each flow”
how??? if the unique ID is same for all flows ?
also can you clarify what d you mean by flow in this article?
Hello Avid
When the term “flow” is used, it is referring to traffic that has the same source and destination address. So in both diagrams in the lesson, there are two flows: one from H1 to H3 and a second from H2 to H3.
Each router has a unique ID that is used for this algorithm. This means that for flow H1 to H2 for example, R1’s algorithm would send the flow via interface 1, R2s algorithm will send the flow via interface 2, R3’s algorithm will send it via interface 3 and so on. In other words, each router would calculate a randomly different exit interface. Conversely, the original algorithm would cause all routers to send the specific flow via the same interface, which can result in CEF polarization.
Now with the displayed examples containing two flows, the benefits of this are not immediately visible. Imagine you have 100 flows, or 1000 flows. The resulting algorithm will more appropriately distribute flows across multiple paths to more efficiently load balance traffic.
I hope this has been helpful!
Laz
1 Like
Thank you so much!!! its Clear now.
1 Like
Hi,
I’m a little confused by how polarisation is avoided.
I get that if you only use source and destination IP then all traffic between two hosts will take the same route, even if they are accessing different services (ports).
And I understand that if you include ports then the above problem is mitigated in that the traffic is will be spread more evenly amongst exit interfaces.
But, unless you use an algorithm that uses the random unique ID, wont polarisation always occur? Because the hash will always be the same. And the same exit interfaces will always be the same on all routers for all flows even if ports are used in decision making.
So, your statement below about the 6500’s makes sense to me because Default is the only one using a unique ID
The full, simple and full simple variations are prone to CEF polarization.
However, the statement before that has confused me
Only the original CEF variation is prone to CEF polarization, the other options avoid it by including other information besides the source/destination IP address.
Because according to the list - original, universal, tunnel, l4 port - universal is the only one using a unique ID and thus the only one avoiding polarisation.
Thanks,
Sam
Hello Samir
I understand what you’re saying here, and if you take a look at only two hosts communicating, then yes you are correct. The use of a unique ID won’t solve this problem. For this particular example, all packets that arrive at R2 will have the same source and destination IPs so any hash calculation at R2 will result in the same exit interface for all packets.
However, the use of the unique ID is not intended to solve the problem when you have only two hosts. Imagine you have 100 hosts communicating. R1 will use its hashing algorithm to load balance routing so that 50 flows go to R2 and fifty flows go to R3. Now if we use the Original or Default variation of CEF, then R2 will receive 50 flows with 50 different source IP addresses but because it uses the same algorithm as R1, it will direct them all to the same interface.
However, if we use Universal, with a unique ID, then the algorithm used by R2 will be different than the one used by R1, and will thus be able to load balance those 50 flows across multiple interfaces. I think that resolves your other questions as well, however, if not, don’t hesitate to ask follow-up or clarification questions!
I hope this has been helpful!
Laz
Hi Laz,
I think I worded my question incorrectly, but I also understood your point for a pair of hosts.
I actually meant that for many hosts communicating with each other, without a unique ID, those hosts will always be assigned the same interfaces on every router along the path. So yes, the unique ID solves that problem for many hosts communicating. But it’s the statement:
Only the original CEF variation is prone to CEF polarization, the other options avoid it by including other information besides the source/destination IP address.
.. that has confused me because of the list (Universal, Original, Tunnel and L4) only Universal is listed as including a random ID. Does Tunnel and L4 use a unique ID that too? Is that what “including other information” in the above statement means?
Thanks for the help,
Sam
Hello Samir
Doing a little more reading about the specific algorithms used for each CEF variation, I have found the following:
- Original uses an algorithm that uses source IP, destination IP, and a common ID hash for all routers
- Universal uses an algorithm that uses source IP, destination IP, and a unique ID hash for each router
- For the Tunnel algorithm, I was unable to get any more specific information beyond simply that it is an improvement to the universal algorithm, and functions better “in environments where there are only a few IP source and destination address pairs.” and in environments where there are many tunnels. As an “improvement” I would assume that it does use a unique ID, or at least a mechanism that is better than the original algorithm. In such cases, it seems that the source and destination addresses of the encapsulated IP packet are not considered at all in the algorithm. The only other available information is from the Cisco website saying that it would perform better than the universal algorithm in tunnel-heavy environments, where the intermediate routers will only see tunnel endpoints.
- The L4 port algorithm uses the universal algorithm but adds the TCP or UDP ports as part of the algorithmic calculation. Because different ports may be used by the same pair of hosts in their communications, this algorithm can even load balance traffic that has the same source and destination IPs!
I hope this has been helpful!
Laz
Hi Laz,
Thanks, that all makes sense.
Sam
1 Like
Hello,
What about if between R1 and R2 (not from this topology, a random topology) you have 2 different paths (a short one, and a long one) and you have one OSPF adj for each path.
If you want Voip and Video packets to be forwarded by the shortest path (physically speaking) due for delay optimization, does it mean you have to do a trial and error with the different CEF load-balancing options ?
What about using LACP ? i think is the same because LACP also use a hash function.
Hello Juan
If you want to ensure that your VoIP and video packets are being treated with priority, simply determining the shortest path and adjusting the operation of CEF and routing for this purpose will not be effective in what you want to do. The shortest path is not always the best. For this reason, it is preferrable that you employ QoS mechanisms that will dynamically adjust to network conditions, and will prioritize the packets you want appropriately. This will relieve you of needing to perform trial and error to ensure that your packets will be delivered appropriately.
Now having said that, there are some guidelines you should follow concerning CEF, regardless of your QoS implementation, to ensure the best results. CEF can be set to function with load balancing on a per destination or on a per packet basis. For applications such as VoIP and video, per destination is preferable, because it preserves packet order to a greater degree, something which is necessary for such applications.
Now if you still want to force particular packets such as VoIP and video over a particular path, then you may want to look into Policy-Based Routing (PBR). With PBR, you can create policies that dictate which path certain types of traffic should take based on criteria like source and destination IP addresses, source and destination ports, and even protocol type. This could give you the level of control you’re looking for.
As for LACP, it’s typically used to combine multiple physical links into a single logical link to increase bandwidth and provide redundancy. The way it balances traffic between the links depends on the specific algorithm used, which could be based on MAC addresses, IP addresses, or even TCP/UDP port numbers. But like with CEF, LACP won’t necessarily ensure that VoIP and Video packets always take the shortest path. But it is preferrable to perform load balancing across such links on a per-destination basis so that the packets of the same voice or video stream will traverse the same physical link, ensuring that they largely remain in order.
I hope this has been helpful!
Laz
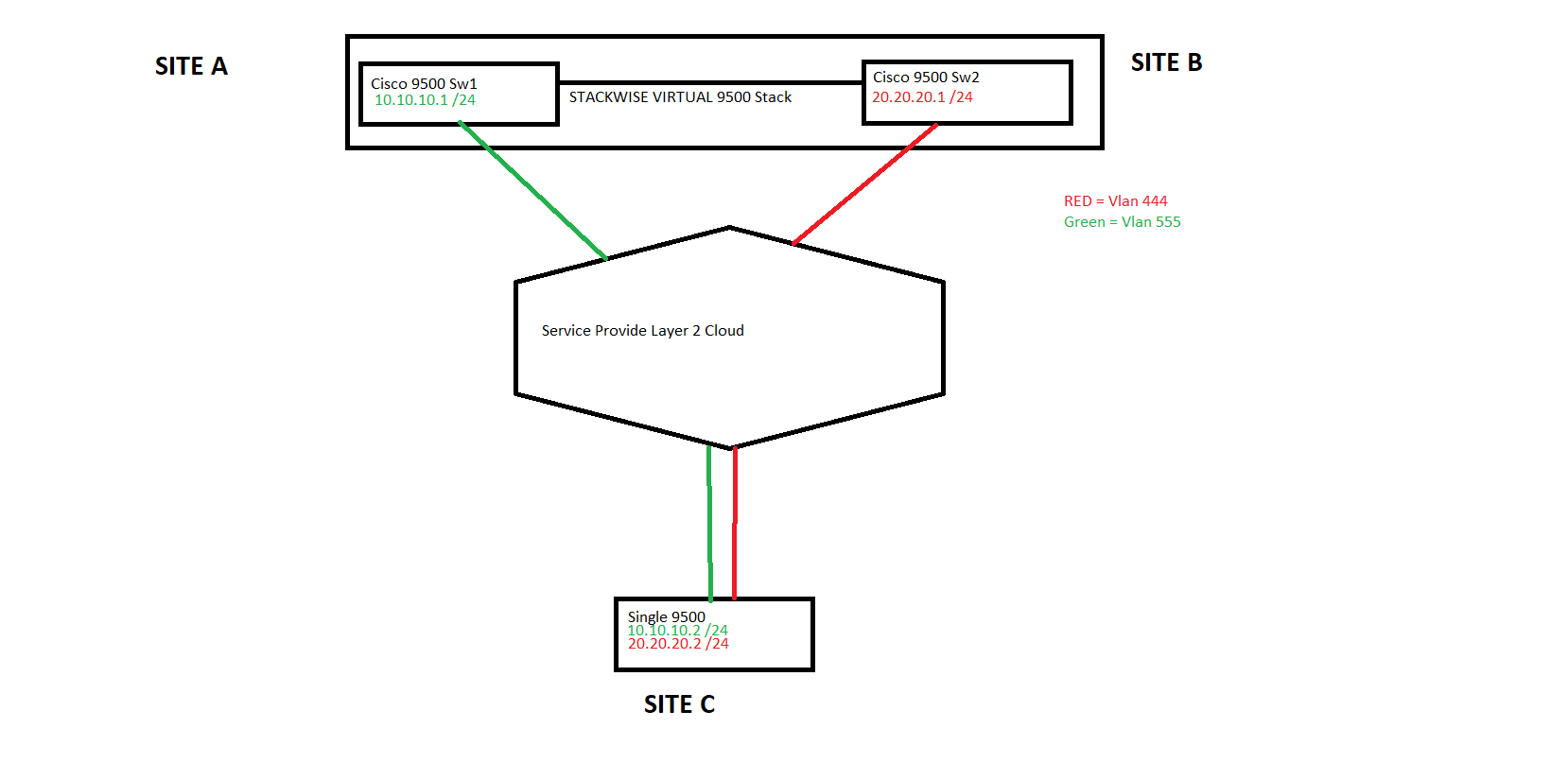
Hi I was just wondering what is the best CEF option for CCTV traffic ?
If I have three sites as per drawing and site C is sending traffic to a destination lan switch (not in the drawing ) which is etherchanneled behind site A and B (which are a pair of 9500s running stackwise virtual) in the drawing.
Site A and B and C all have an entry point into a layer 2 service provider p2mp cloud.
I am routing Eigrp with SVI’s for two vlans 444 and 555
Site C will send the traffic but
What is the best way to utilize cef for delay sensitive traffic ?
Thanks
Hello Sean
CEF is an advanced Layer 3 switching technology used in networks. For delay-sensitive traffic such as CCTV, the best way to utilize CEF would be to enable per-packet load balancing. This ensures that each packet is evenly distributed across the available paths, reducing the chance of congestion, and therefore minimizing delay.
Video services typically use UDP for efficient transmission, without regard to the possibility of receiving packets out of order. Video is typically quite resilient to out-of-order delivery and even to some packet delay or jitter with little or no effect on quality. However, if per-packet load balancing causes extreme out-of-order arrival of packets or a high level of jitter, it can eventually affect video quality. If your topology results in such behavior due to the different paths and varying latencies, it may be necessary to consider using per-destination load balancing instead. This method ensures that all packets of a single video stream take the same path, aiding in preserving their order.
So although theoretically speaking, per-packet load balancing should be ideal, this doesn’t take into account the additional parameters of the topology that can only be determined practically by experimentation.
Other than CEF, you must also ensure that you appropriately prioritize your CCTV traffic using QoS. QoS can help ensure that your delay-sensitive CCTV traffic is given priority over less time-critical traffic.
I hope this has been helpful!
Laz
1 Like
Hi Laz,
Ok, I think I finally get this - 4 years after originally asking the question! CEF Polarization - #8 by samirkhair
Basically, load balancing will occur on the first hop for different SIP + DIP traffic flows, but because the algorithm computes to the same value for every other router after, it will be the same exit interface along the path. So, for example, if 50 different SIP+DIP flows use Gi0/1 on the first router, they will also use Gi0/1 across every router the destination, so no load balancing occurs beyond the first router.
Using a router-unique hash means for all those different SIP+DIP flows will now compute to use potentially different interfaces on each router along the path, so load balancing will occur for different SIP + DIP routers after the first hop.
Is that all correct?
Sam
Hello Sam
Yes, that’s exactly it! CEF polarization occurs when the per-flow hashing algorithm used by CEF results in the same interface selection across multiple hops, negating effective load balancing beyond the first router.
The solution as you suggest is a router-unique hash, resulting in potentially different interfaces being used on each router along the path. Good job!! ![]()
Laz
1 Like