About this sh ip bgp output on this lesson:
I’ve marked in bold both “i” codes, one after the best path symbol “>” and the other in the Path column. What’s the difference between them ? there are 2 codes, one internal uses the same letter “i” and the other is the origin code it uses the letter “i” too . I also know “internal” means that the route is learned via iBGP and igp is for routes locally originated.
R4#show ip bgp
BGP table version is 2, local router ID is 4.4.4.4
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
*>i1.1.1.0/24 2.2.2.2 0 100 0 1 i
This weekend i’ve tried this topology but i made a little changes. R2-R3-R4 (ASN2) IGP configuration using OSPF but R2 is Area 1 Stub , R3 is the ABR (lo0 3.3.3.3 in Area 0) link 192.168.23.0/24 in Area 1 stub , link 192.168.34.0/24 in Area 2 Stub, and R4 Area 2 stub :
R4 installed the 1.1.1.1/32 (announced via eBGP from R1 to R2) with next-hop 192.168.12.1 but R4 hasn’t specific route (for example the 192.168.12.0/24 subnet) for 192.168.12.1
I’ve always tought BGP Speaker while doing the recursive lookup to the BGP next-hop must has specific route into the RiB for that BGP next-hop .
I was wrong : R4 installed that route due the default route injected by R3 (OSPF ABR), so then i issued no area 1 stub (on R1 & R3) and no area 2 stub (on R3 & R4) therefore using normal OSPF areas and the ABR no longer inject the default route , now the 1.1.1.1/32 isn’t installed into the RiB because its no longer has any entry into the RiB (specific nor default route) for the BGP next-hop
The BGP table can be confusing, especially when they use the same letter “i” for multiple indicators!
So the leftmost “i” that appears before the prefix destination is the Status Code. This indicates that the route was learned via iBGP.
The rightmost “i” at the end of the entry is what is known as the Origin code. This is useful when we look at the Origin Code Attribute of BGP. The following two NetworkLessons notes clarify these indicators and how they appear in the BGP table:
Thanks for sharing your experience with your topologies! This is useful information. Let me go over some of the mechanisms that are being applied here to get the results you see.
Actually, BGP will check the routing table to see if there is a valid route to the next hop. A default route is still considered a valid route to the next hop. When you had stub areas configured, R4 had a default route automatically added to the routing table. However, when you removed this configuration, that default route was also removed, thus BGP no longer has a valid route to the next hop address.
Now in your scenario, the next hop for the 1.1.1.1/32 network from R4 was 192.168.12.1, which is R1. Even though there was a default route, I believe that this address would still not have been reachable, since the 192.168.12.0/24 network is not advertised using BGP, correct? Or OSPF for that matter. So connectivity would still fail. Keep in mind that the point of this lab is to see how prefixes are installed in the routing and BGP tables, and not necessarily how traffic is successfully routed… Does that make sense?
Why do we have to use IGP? Why can’t we only use iBGP in all routers inside our transit AS and advertise prefixes using network command, for reachability of packets coming from eBGP?
This is an excellent question. The truth is that we can use BGP to route traffic within an AS. However, BGP is not designed to be as fast in converging as IGPs. Its timers can be adjusted, but even so, its convergence time would be on the order of several seconds compared to milliseconds that are achievable with IGPs. So in general, it would be too slow to respond to the needs of routing internally in an AS.
For this reason, it is best practice to employ an IGP within an AS and BGP between ASes. Take a look at these NetworkLessons notes on the topic for more information:
My ENARSI OCG book mentions the following: Redistributing iBGP routes into an IGP could result in routing loops. A more logical solution is to advertise the network into the IGP.
How exactly could a routing loop occur if we were to redistribute an iBGP-learned route into an IGP like OSPF, for example?
The possibility of routing loops occurs because of the fundamental differences in how iBGP and IGPs like OSPF handle routing information.
In iBGP, routes learned from one iBGP neighbor are not advertised to another iBGP neighbor. This is known as the iBGP split-horizon rule. The purpose of this rule is to prevent routing loops within the AS.
On the other hand, IGPs like OSPF do not have this rule. They advertise all learned routes to all neighbors. So, if you redistribute an iBGP-learned route into OSPF, OSPF would then advertise this route to all its neighbors, including the iBGP router that originally advertised the route. This could potentially create a loop.
Let’s take an example: Router A learns a route from iBGP peer Router B. Router A then redistributes this route into OSPF. Router C, an OSPF neighbor of Router A, learns this route and advertises it to its iBGP peer, Router B. Now, Router B has a looped route.
The more logical solution, as the ENARSI OCG book suggests, is to advertise the network directly into the IGP and not redistribute. This means that instead of redistributing specific routes from iBGP into OSPF, you directly advertise the network that these routes belong to. This way, all routers in the OSPF domain will have a route to the network, and you avoid the potential for routing loops.
This brings into light the design principles of the operation of BGP and how it relates to IGPs.
IGPs are typically used to route traffic within an AS while BGP is used to route traffic between ASes. The role of iBGP is simply to learn about the routes in the local AS and inform the eBGP routers on the edge of the AS of those routes, so those routes can be advertised to external ASes. iBGP typically plays no role in the routing mechanisms within an AS.
Great lesson as always. This one took me a few tries to lab up and understand. As for iBGP, not sure why iBGP designers couldn’t just create another attribute to use during config to prevent loops. Also , other then the full mesh config, is the difference between BGP and iBGP, syntactically, just using the same AS number for iBGP?
The loop prevention mechanisms for iBGP involve either the creation of a full mesh, the use of route reflectors, or the use of confederations. These in conjunction with the iBGP split horizon rule ensure that within an AS, iBGP does not create loops.
The reason iBGP designers didn’t just create another attribute to prevent loops is because BGP was designed to be a path vector protocol, which means it needs a way to prevent loops at the AS level. The loop prevention mechanisms in iBGP are different from eBGP because iBGP assumes that it’s running within a single AS.
Yes, that is correct. Syntactically, iBGP is by definition operating between BGP peers in the same AS, while eBGP is operating between BGP peers in different ASes. It’s the same protocol, but they behave a little differently when the peering is with a router in the same AS or a different AS.
I understand the network command on R1 is for the advertisement, but why there is no need to use update-source command here?
Also I am wondering (A bit confused), in configuring BGP, after setting up neighbours, do we not need to do the network routing configuration like OSPF or EIGRP?
If you don’t use the update-source command, then the BGP process will use the exit interface to reach the neighbor as the source. In other words, the neighbor 192.168.12.2 remote-as 2 command will examine the 192.168.12.2 neighbor address and determine the exit interface that must be used to reach it (from the routing table). The exit interface is Fa0/0 which has an IP address of 192.168.12.1, so that will be used as the source for all BGP exchanges with that neighbor. If you want to change this behavior, to use a loopback address or another interface, then you must use the update-source command. An example of how this command is used can be found in the iBGP update source section of the Troubleshooting BGP Neighbor Adjacency lesson.
In order to have iBGP function correctly within an AS, one of the prerequisites is that all iBGP routers within the AS are reachable to each other. This is generally achieved using an IGP like EIGRP or OSPF, or it can be done using static routing. Just as long as all iBGP routers can reach each other, iBGP will function. In the lesson, Rene used OSPF to ensure that R2 and R4 in AS2 are mutually reachable.
eBGP does not generally need this because eBGP routers are typically directly connected. They exist on the edge of an AS and interconnect multiple ASes as shown in the lesson. There are exceptions to this rule of course, but I won’t go into detail here.
Thank you so much for your kind answers, they are very clear and helpful.
One more question, you said EBGP routers are directly connected, do you mean they are physically connected to each other without any intermediary devices like routers or switches, or can you connect eBGP via static routing?
Yes, that is typically the case. eBGP is primarily designed to have the routers physically directly connected to each other. That way, ASes are directly connected to each other. If you try to create an eBGP peering between two eBGP routers with multiple intermediary routers in between, by default, such a peering will fail. eBGP messages are sent with a TTL of 1, so no eBGP peering can be created with multiple hops in between.
However, you can override this default behavior with the eBGP multihop feature. You can find out more about that here:
So to my understanding we use iBGP in a transit as so we can have as 1 communicate with AS3 in the video. Without this then R1 would not be able to reach AS3. We use iBGP to avoid having to redistribute because this would cause issues then correct? Theoretically you could just use igp, but it can’t handle that many routes. So in iBGP we use IGP as a way to dynamically learn the routes instead of creating static routes since bgp cannot do that and is used for hopping to another AS.
So usually when configuring an iBGP there is typically an IGP or static route configured underneath to provide connectivity and also be able to share those routes to different autonomous systems only within the bgp table? Am I understanding this correctly?
Is ebgp-multihop needed for iBGP or is the TTL different for iBGP since it learning routes say with OSPF.
The primary point of BGP is to travel to different ASes and iBGP is to make it so that when you are travelling within an autonomous system to keep those routes to different autonomous systems seperate so the routers aren’t overloaded with so many routes and just know the internal routes for their AS they need to know?
For the most part, you have a good understanding of how BGP works. Let me just mention a couple of things in response to your comments:
Yes you are up to this point.
eBGP has the TTL check to ensure that the eBGP neighbor is directly connected. iBGP has no such check. iBGP routers can be several hops away from each other and there is no mechanism that checks this. The prerequisite is that within the AS (for example AS 2 in the lesson), all iBGP routers must have a full mesh of peerings. Since that is the case, that means that R2, R3, and R4 must be able to reach each other to form these peerings. How are they reachable? Using an IGP or static routing. So the multhop feature of eBGP is unnecessary for iBGP.
It looks like your understanding of the rest is very good. Nice job!!
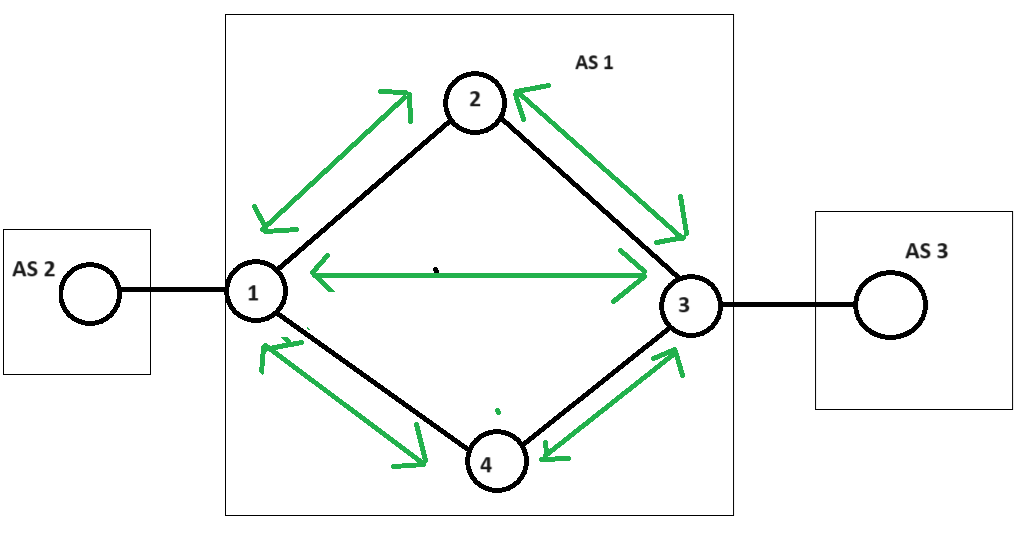
I just want to clarify that you only need to mesh between routers that have eBGP connections (or use the network command) to achieve full connectivity, correct? e.g. In the topology below, creating a neighbor relationship between routers 2 and 4 serves no purpose:
Assuming that AS1 is used only to share routes between AS2 and AS3, you’re right, you could create iBGP peering between routers 1 and 3 (assuming routing between these routers is established using an IGP or static routes). However, if AS1 has routes within it that need to be shared with other ASes, then routers 2 and 4 should also form iBGP peerings in a full mesh fashion. Or if you have a customer that is connected to router 4 and they need to learn about routes from AS2 and AS3, router 4 must become an iBGP peer to receive those routes. Does that make sense?