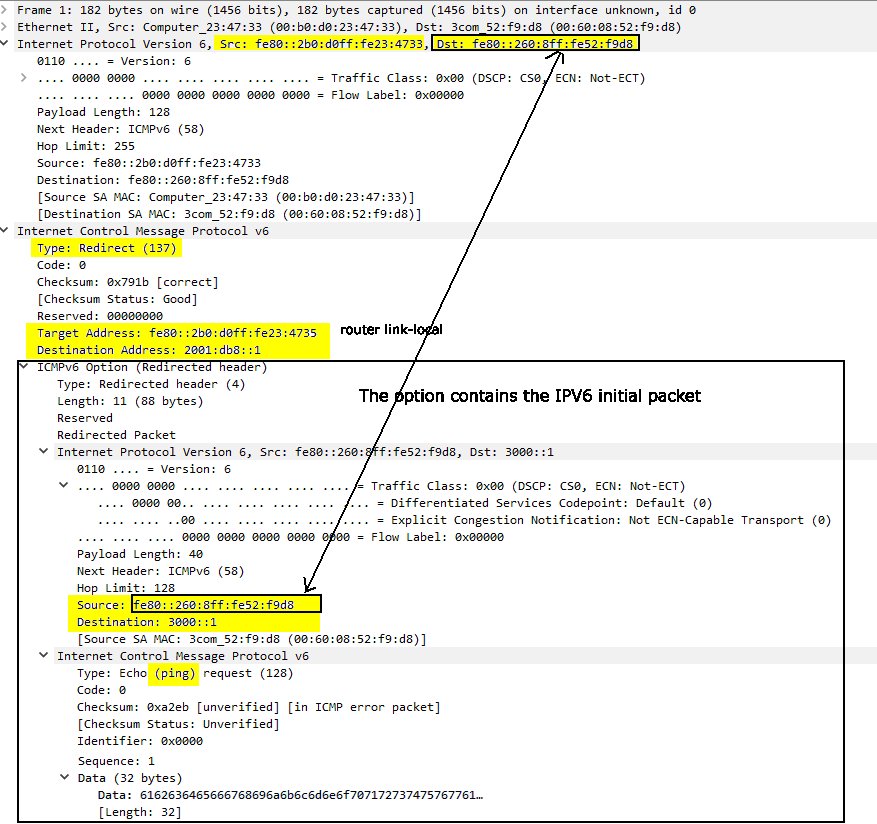
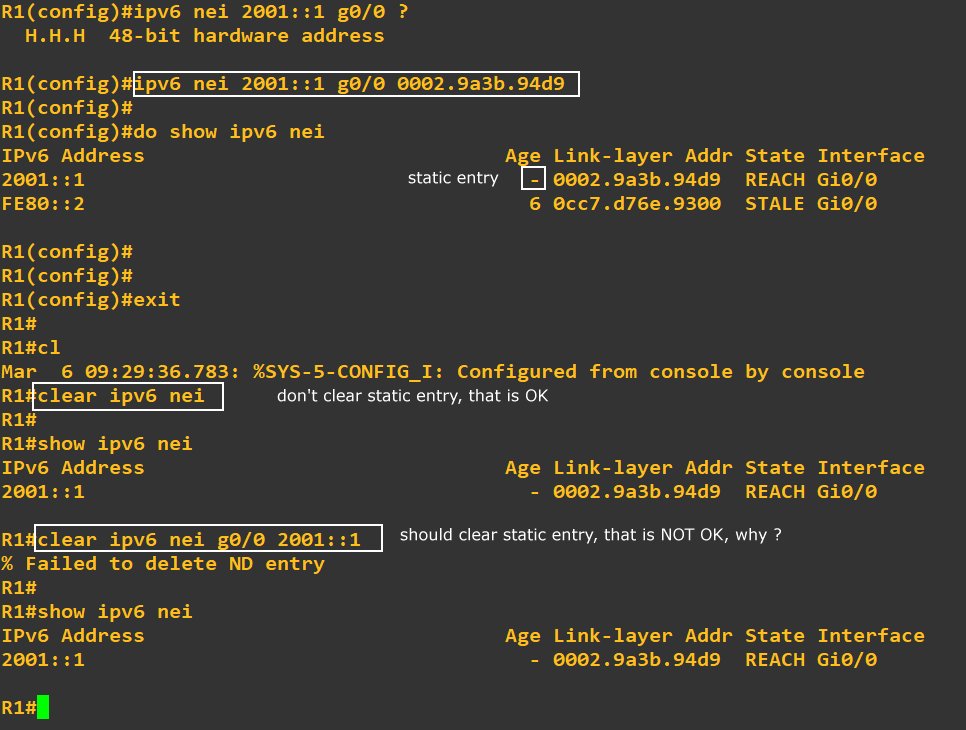
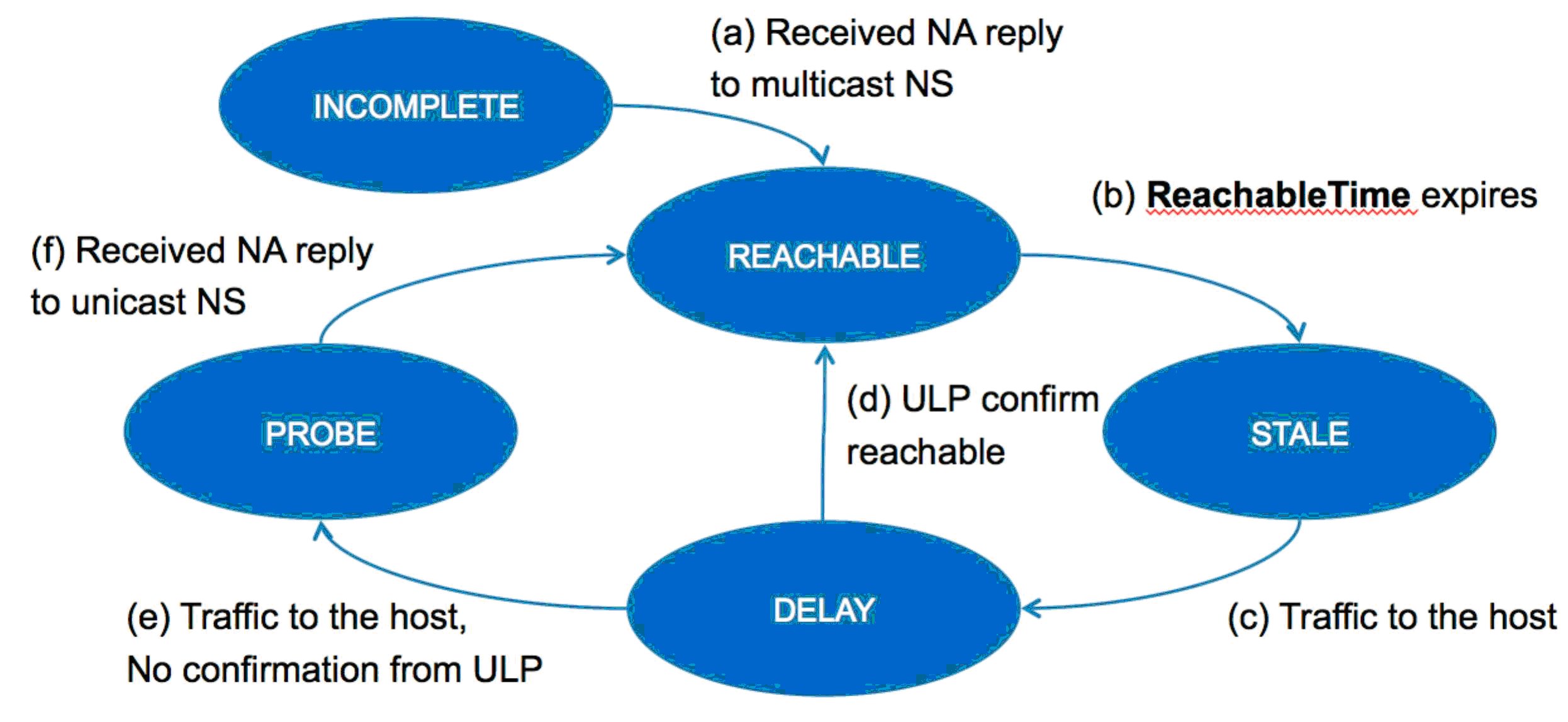
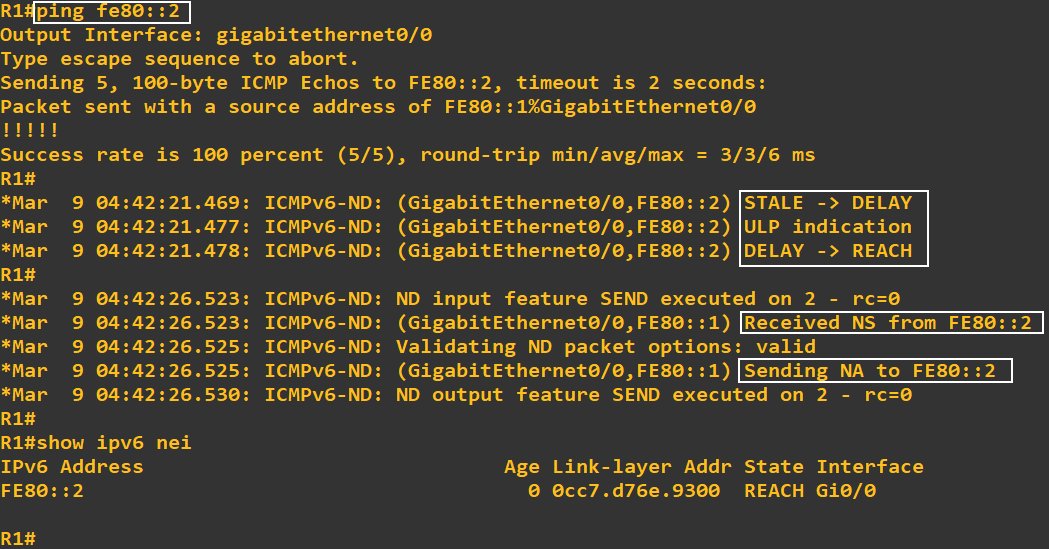
Hello Dominique
It’s great to see how in depth you get into these subjects to fully understand what is going on, that’s great!
I went into RFC4861 which describes these features of NDP to examine your question further. I also did some more digging in RFC5942 which was very enlightening as well.
The fundamental principle behind this has to do with the fact that in IPv4, if you have an IP address and a subnet mask, this is enough information to determine if that address is on the same segment, or “on link” as another address. This is not the case with IPv6. As stated in the latter RFC,
“The on-link determination is separate from the address assignment.”
The RFC goes on to say:
The reception of a Prefix Information Option (PIO) with the L-bit set [RFC4861] and a non-zero valid lifetime creates (or updates) an entry in the Prefix List. All prefixes on a host’s Prefix List (i.e., those prefixes that have not yet timed out) are considered to be on-link by that host.
So when L = 1 (as you already stated), the prefix in question is considered unequivocally to be on-link, and thus it is added to a host’s Prefix List.
Now according to RFC4861, if L = 0, this does not mean that the prefix is off-link. In other words, if an address is derived from the prefix in question, it simply states that “I don’t know if it is off-link or on-link”. This means that if L = 0 for a particular prefix, such an RA must not update a previous indication that this particular prefix is on-link. So if you have, in a host’s prefix list IPv6 address A, and an RA arrives with the same prefix as address A and L = 0 in that RA, you must not update your prefix list. Take a look at the Host Behavior section of RFC 5942 as it is indeed informative.
Now what does this mean? Well, if L = 1, then the prefix enters the prefix list, and any communication with IPv6 addresses of that prefix will be sent directly. That is, no default router is involved. If L = 0, no change in the prefix list takes place. If the prefix expires (times out), then any future communication with that prefix must take place via the default router. I think this is the behaviour that you were were describing as a PVLAN-like behaviour.
I hope this has been helpful!
Laz