Hello Daniel
This is not a silly question, but an opportunity! I have found that I still sometimes need to get my head around these MTU concepts to clarify them, so this is just another chance to do that!
I think the key confusion here is mixing up TCP segmentation (which is good) with IP fragmentation (which we want to avoid). Let’s break it down.
The MTU = 1500 bytes on standard Ethernet. This is the maximum size of the entire IP packet (headers + data) that is encapsulated within the frame. This is used during encapsulation from L3 into L2.
The TCP MSS = MTU - IP header - TCP header which for standard Ethernet is 1500 - 20 - 20 = 1460 bytes. This is the maximum amount of application data in one TCP segment. This is used at L4 for the process of segmentation.
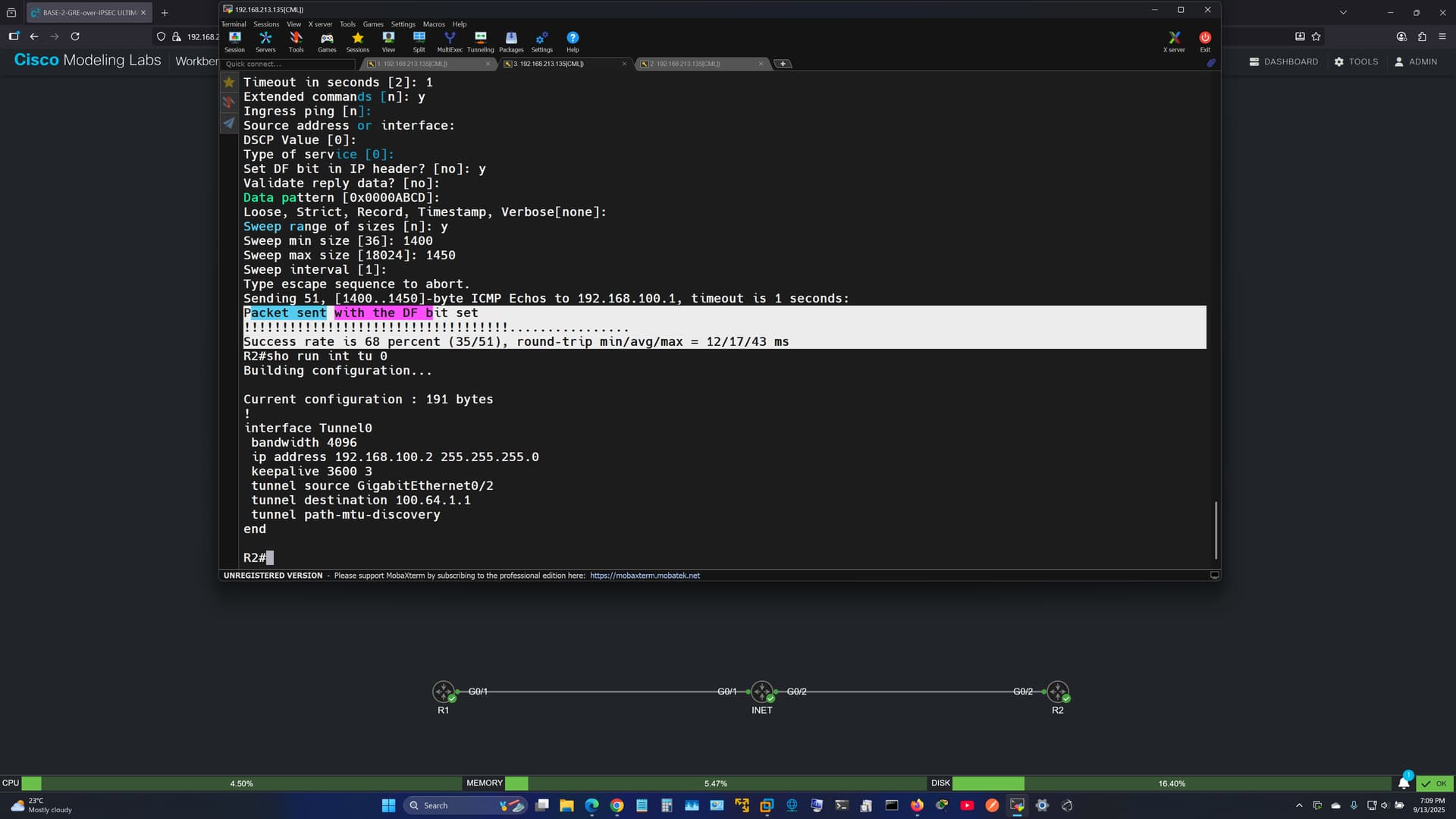
Now, for your 15,000-byte example, when you send 15,000 bytes of data with an MSS of 1460, TCP divides or segments 15,000 bytes into approximately 11 segments (15,000 ÷ 1,460 ≈ 10.27). Each segment is encapsulated into one IP packet with 1460 data + 20 TCP header + 20 IP header = 1500 bytes. The result is 11 separate packets, but zero fragmentation!
Now let’s look at your core question: “If I reduce my TCP-MSS I’m not increasing fragmentation?”
That is correct! Reducing TCP MSS actually prevents fragmentation, not increases it. TCP segmentation at L4 is good. It happens at the source host before sending. TCP intelligently divides application data into MSS-sized chunks and it creates multiple complete, independent packets.
IP Fragmentation at L3 is bad. It occurs at intermediate routers when an IP packet exceeds the link MTU. A router must break one packet into multiple fragments, which causes performance problems.
When you reduce MSS, it makes the underlying IP packets smaller, thus reducing the chance of fragmentation. Indeed, TCP already respects the MSS before creating packets, so fragmentation never happens in normal TCP communication unless something changes the path MTU. Make sense?
I hope this has been helpful!
Laz