Hello David
Let me try to add some detail to the process:
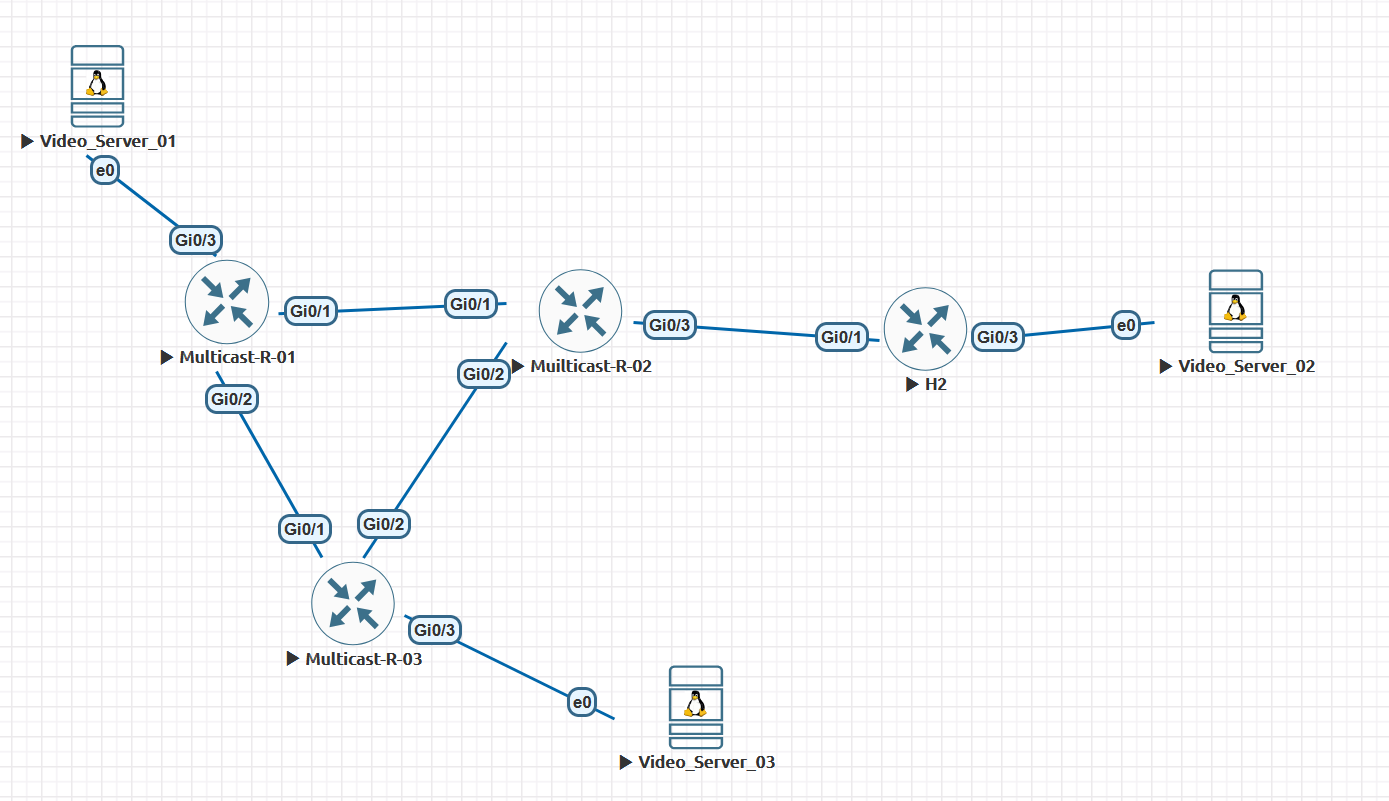
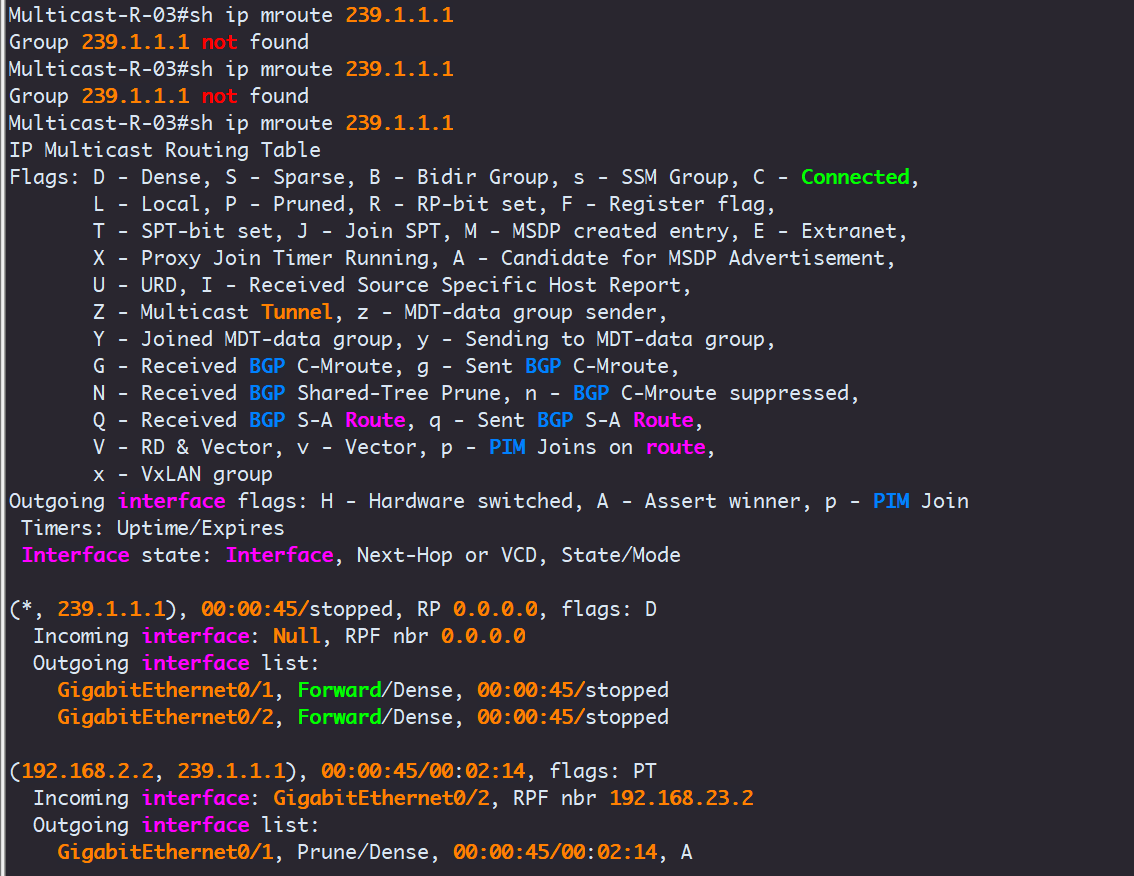
PIM-DM routers exchange periodic Hello messages, by default, every 30 seconds, to maintain neighbor adjacencies. If a neighbor fails (detected via Hello timeout), the router removes the neighbor from its PIM neighbor table. When a neighbor goes down, the router removes the associated interface from the OIL for multicast groups. Upstream routers will prune the affected branch if no other valid OIL interfaces exist, suppressing traffic until the next flood cycle.
By default, PIM-DM re-floods multicast traffic every 3 minutes. This occurs when prune states expire, resulting in the rebuilding of the distribution tree. With State Refresh enabled, periodic refresh messages, by default: every 60 seconds, extend prune timers, reducing unnecessary flooding.
Now, after a failed link recovers, a downstream router sends GRAFT messages upstream to rejoin the multicast tree, bypassing the flood cycle. Upstream routers reinstate the interface in the OIL upon receiving GRAFTs, resuming traffic immediately.
So the router does not globally prune out all groups for every neighbor when one neighbor goes down. It just discontinues sending traffic to that specific neighbor. Graft messages are the “recovery” trigger, telling the upstream router, “I realize I got pruned or was offline; now I need the multicast traffic again on this interface.” If a Graft message is not sent, and the prune timers expire, the traffic begins to be sent once again. Does that make sense?
I hope this has been helpful!
Laz