Hi,
I had worked this lab in IPV4 before but when I got to this I was confused a bit.
You had the following:
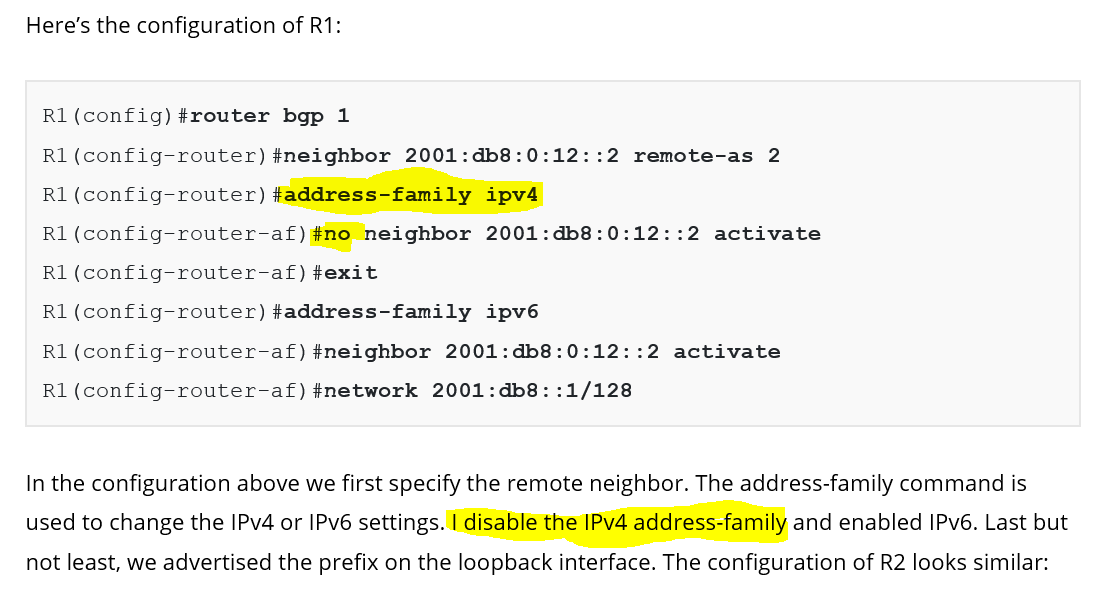
I see that you go into the address-family ipv4 and I am good there but then I see you do the no activate on the ipv6. Here is where I am confused; have yet to find granular details and also checking my kindle book for info as well:
Doyle, Jeff. Routing TCP/IP, Volume II: CCIE Professional Development: CCIE Professional Development: 2 (Kindle Location 15220). Pearson Education. Kindle Edition.
The Kindle books has this in bold at the top:
IPv4 and IPv6 Prefixes over an IPv4 TCP Session
From the title it seems to suggest that IPV4 and/or IPV6 create TCP sessions and you can send IPV6 prefixes as well as IPV4 prefixes over the session regardless of type.
Think of these as just prefixes in essence objects if you will that are being passed over TCP (transport layer) session.
below is a picture I found to help visually explain this from my kindle book as well.
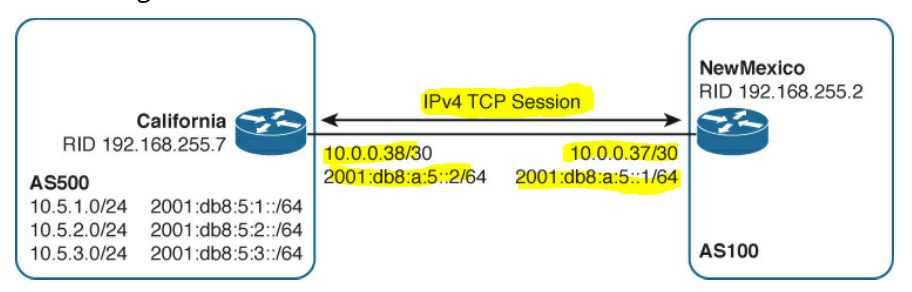
Let me know if this is correct thinking.
I started thinking… IPV4 is 32 bytes and IPV6 is 128bytes… now I know we are talking about layer 4 which is the transport layer so I guess you just stick the 128byte into the transport layer TCP but then wouldn’t it be called TCP/IPV6 instead of TCP/IP?
I actually have never thought about IPV6 in regards to the OSI model…
Went back and read all the forums post a second time and now after I am on the right track I see that a few others was talking about this as well. Not sure why I didn’t pick it up the first time.