Hello Rene/Laz,
I have a few questions and I am going to use the below topology as the reference.
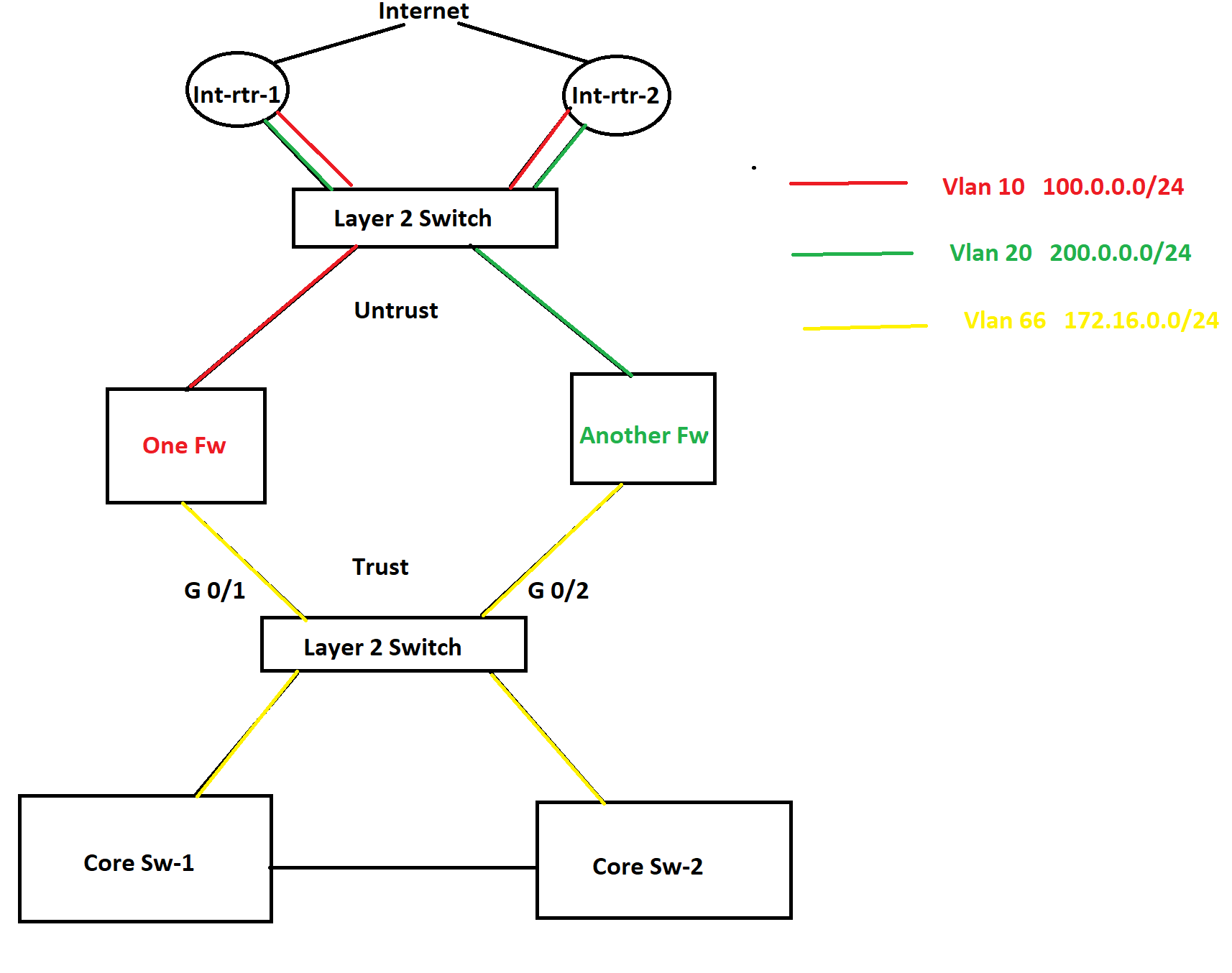
In this topology, there are two internet connections as you see in the picture and HSRP is configured between them. One router is active for one VLAN and another router is active for another VLAN is HSRP. There are two different firewalls for two different purposes. In this scenario, a lot of packet discards are being observed in the Trust zone and Untrust zone both because of bandwidth saturation. No port-channel can be configured anywhere as part of the requirement. Besides this, some TCP application traffic can not have any delay/slowness and those applications are sitting in the internet cloud. In this situation, I was thinking to configure QoS on port G0/1 and G0/2 and prioritize the applications. However, I was thinking to configure QoS policy based upon the ACL that consists of source and destination IP addresses since no device is marking these applications traffic anywhere in the network. What do you think about this? If you have any better solution, please let me know as well.
Now let’s move onto the second question. As you see in the diagram, there are two different VLANs in the Untrust zone which are using two different subnets of public IP address and they both are being advertised by both internet routers to the internet. I was thinking to configure GLBP in place of HSRP so both firewalls can use both internet circuits simultaneously. Note that both of the internet connections belong to the same service provider. What do you think about this solution? Again if you have a better solution, please let me know. Thanks in advance.
Azm