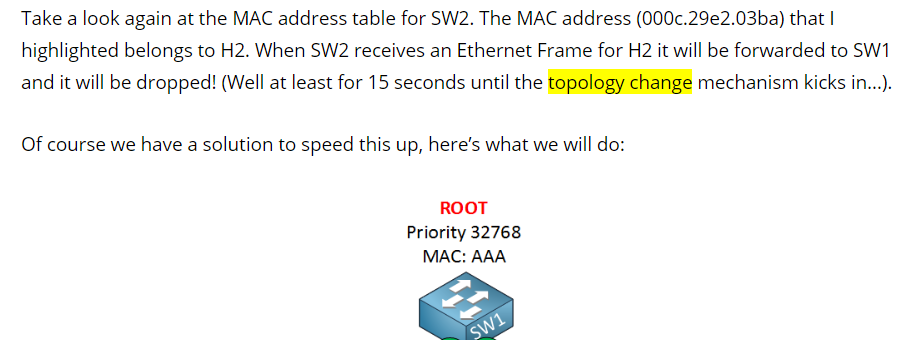
The link failure is also detected on SW1 however, the example examines the behaviour of the ports on SW3.
In the diagram, @ReneMolenaar still has the (D) showing up on port fa0/17 on SW1, and this should be removed. I will inform him…
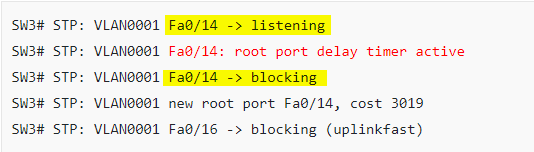
SW3 does sent a TCN to SW1 but not necessarily immediately. Note the SW3# STP: VLAN0001 Fa0/14: root port delay timer active debug line.
The last diagram does not indicate what the states of the ports on SW3 are in order to make a point of determining them from the debug. As mentioned in the text: “You can see we don’t immediately switch back to interface fa0/14. There’s no reason to switch back to this interface ASAP because we have a working root port.”
Eventually, the Fa0/16 does become blocked and the Fa0/14 does become the root port with a cost of 3019.
Does sw3fa0/16 going forwarding create a TCN as well and we don’t require the dummy multicast frame? or this is classic stp with uplinkfast enable and not RSTP?
The rstp lesson mentions:
With the classic spanning tree a link failure would trigger a topology change. Using rapid spanning tree a link failure is not considered as a topology change. Only non-edge interfaces (leading to other switches) that move to the forwarding state are considered as a topology change ( in this case sw3 fa0/16). Once a switch detects a topology change this will happen:
•It will start a topology change while timer with a value that is twice the hello time. This will be done for all non-edge designated and root ports.
•It will flush the MAC addresses that are learned on these ports.
When the link fails, SW3 will indeed send a TCN. If you notice earlier in the lesson, just before the multicast frame mechanism is explained, Rene mentions this:
So without the dummy multicast frame mechanism, the flushing of the MAC address table will take 15 seconds due to the TCN, as opposed to the 300 seconds it would normally take. However, the dummy multicast frame improves upon this by updating the MAC address tables of the connected switches almost instantaneously.
There are two situations where the re-convergence takes place. The first is in the case of the lesson, where when port fa0/14 is shutdown, there is a complete carrier loss. In this case, the port with the best BPDU information is immediately invalidated. This means that the next best port is immediately chosen, which is fa0/16 without delay, so no 20 seconds are wasted in blocked mode. This is why the transition took 30 seconds, 15 in listening and 15 in learning.
Now if there were another switch between SW1 and SW3, and that switches connection to SW1 failed, fa0/14 would still be active, so no immediate loss of connectivity would be detected by SW3. This means that the whole BPDU exchange process would have to inform SW3 that more valid BPDUs are being received now from fa0/16, so it would then transition using the blocked>listening>learning procedure of 50 seconds.
The Max_age timer plays a role when the current root port of the local switch is still up, but a failure has occurred somewhere else upstream. Only then will the Max_age timer need to be exhausted before a port considers the last BPDU it has received invalid. This is also related to the previous post:
Hello Laz,
then what is the purpose of the Max Age timer if the port fa0/16 will move directly to the listening state after that the switch realizes that fa0/14 went down?
My undestanding (and please correct me if I am wrong) is that by default the switch will wait for 20 seconds for fa0/14 to come up again. Only after that the switch will start with the STP recalculation.
Regards,
Fadi.
In the scenario that is being described, the port that actually goes down (Fa0/14 on SW3) is on the same switch as the port that is changing state (Fa0/16 on SW3). This means that the switch immediately knows that the current root port is no longer valid, therefore it doesn’t wait for the extra 20 seconds.
If the port that goes down is found on another switch that is upstream in relation to SW3 and the root bridge, then the switch does not immediately know that it’s ND port should begin changing state, so it waits the extra 20 seconds making the total wait time 50 seconds…
According to the next lesson Backbone fast is enabled on all SW. What about Uplink fast? In the example topology of this lesson Uplink fast was enabled only on the SW3 with ND port. Please clarify me.
When Fa0/14 comes back up, Fa0/16 is already a functioning root port. In order for Fa0/14 to become the root port, it must go through the process of exchanging BPDUs with the root switch to determine which port will end up becoming the root port. Because this process takes time, and because you should not have two root ports functioning at the same time, SW3 detects that Fa0/14 is connected to another switch (it receives BPDUs). Thus, it goes into the blocking state to prevent any loops from forming. While in the blocking state, BPDUs are exchanged, and STP goes through the normal convergence process, until Fa0/14 is determined to be the root port.
Notice that in this case, uplinkfast does not come into play because there is already a working root port. Uplinkfast will only kick in if the functioning root port goes down. Only then will the ND port switch directly to forwarding. But here we have a working root port, so the normal STP convergence time is used.
Unlike backbone fast, by default, uplinkfast is disabled on Cisco switches.
If you are using standard STP, then it is a good idea to use uplinkfast. However, a better practice is to enable RSTP. RSTP contains improvements similar to uplinkfast that are part of its algorithm. The result of these is a vastly improved convergence time, and this is one of the reasons it is called Rapid STP. For more info on RSTP, take a look at this lesson:
I want to know is there no use of TCN concept here b/c as we know whenever topology changes switches send TCN and try to minimize the aging timer but as per this post whenever indirect link failure occur SW2 send BPDU which is inferior according to SW3,
please clarify this whole thing ?
Actually, yes, the TCN is indeed working here. In this case, the link between SW1 and SW3 goes down, and SW2 still has the MAC address table entry for H2 via SW1 for 15 seconds. In this particular topology, the link failure occurs on a port found on the root bridge itself (SW1). This means that there is no need for a TCN to be sent to the root bridge, it detected the topology change itself. So it immediately sends a BPDU with the TC bit set to SW1, and SW1 reduces its MAC address table timer to 15 seconds.
But the problem is that 15 seconds in this case is too long! So another mechanism is required to allow for faster reconvergence in such a situation, and that mechanism is uplinkfast.
No, you don’t need the failed link to be connected directly to the root bridge. I can be between two switches that are not root bridges.
Hi René and all the team and happy easter!!!,
I followed the lab and was wondering if I could “see” the dummy multicast frame sent by SW3 when it switches its ports to inform other switches about its mac-address table but I was not able to see anything of that kind (I mean with the source mac address of H2) in wiresharck, am I missing something or is this frame hidden or encapsulated in something ?
Regards
Fred
If you are using SPAN to capture your packets, in order to capture control packets such as those used for STP (and for CDP, VTP, and others) you must use the encapsulation replicate keywords at the end of the destination port command. Take a look at this post for more info.
But you must keep in mind that for emulation programs such as GNS3 and Virl, from a short search that I have done, I see that most users are unable to capture those multicast packets. It could be simply a limitation of the emulators. You’ll need real equipment to capture them.
You can see an example of such captured packets at this Wireshark packet capture:
The specific packets you want to look at are those that state STP-UplinkFast in the Destination MAC column of the list of packets.