First, take a look at this post that describes a bit about the probes that are sent.
For Cisco IOS devices, you can use extended traceroute commands to change the number of probes sent for each hop. More on this can be found at this Cisco documentation. In the lesson, the number of probes was adjusted on the Linux device.
The TTL that is used when responding to an outgoing traceroute packet doesn’t have any TTL restrictions. This means that the response sent will use a normal TTL that would be used by the device when sending out any type of packet. Now each device and operating system has a different default value for the initial TTL that is used for normal packets. You can see that the routers use an initial TTL of 255 for their responses. When R2 responds, the TTL that reaches the H1 is 254 as expected, and that of R3 is 253 because of the number of hops between those devices. But the server responds with a TTL of 125 when it reaches H1. This is because, the operating system of S1, which is obviously different than that of the routers, decides to use a default TTL of 128 (minus the three hops traversed = 125).
OK laz, but is TTL configurable or not (Both on System and Router if yes then how) as well as when PC sending packet with TTL=1 and it reaches to R1 which reply back with TTL exceeded mean TTL received by R1 is 1 and when it will forward this packet to next hope with TTL=0 therefor I think R2 should respond with TTL exceeded message
*Also Let me know what devices can be considered as Hop like router as well.
As we know we use so many devices from L1 to L7 in our network.
I almost understood probe concept but I also wanna know that if suppose source sending ICPM echo request with TTL value which is reachable to destination in that case shall PC send first 3 icmp packet to R1 and will get 3 reply as well and so on to the next routers?
And as per first scenario i used in question earlier I think 1,2,3 indicating hops and if we do not use probe do normal ping w/o indicating probe then in this case the ip address will be seen 3 times like 192.168.12.2 0 msec 192.168.12.2 1 ms 192.168.12.2 2 ms etc?
I am Right ?
When using traceroute, you cannot adjust the TTL yourself. TTL is used in a specific way for traceroute, and if you change that, traceroute will not function correctly. For normal traffic however, both Windows and Linux allow you to change the default TTL. Doing a simple search online I have found that:
netsh int ipv4 set glob defaultcurhoplimit=129 netsh int ipv6 set glob defaultcurhoplimit=129
For Linux:
sudo sysctl net.ipv4.ip_default_ttl=129
For Cisco, I believe that you cannot change the default TTL, but I was unable to find any documentation confirming or denying this.
All of this has to do with when is the TTL decremented, and when is it considered expired. Take a look at the following post that describes how TTL is handled by routers, including the order of operations concerning routing and decrementing the TTL. The post has to do with eBGP multihop, but the TTL concepts are the same:
TTL is a parameter that is found in the IPv4 or IPv6 packet header, therefore it is exclusively a Layer 3 mechanism. Therefore TTL will be decremented whenever a packet is routed.
Keep in mind that ICMP echo requests and traceroute are not the same thing. An ICMP echo request (ping) only sends a single probe, and the TTL is always the maximum. Only traceroute will send multiple probes with incrementing TTLs. If the TTL on the traceroute is enough to reach the destination, it will indeed (by default) send three probes to which the destination will respond.
1)Will traceroute always send 3 probes to each hop to reach destination whether the routers in the n/w are reachable or not?
One more thing is that when PC sending traceroute with TTL 1 and when it reaches to R1 I think R1 must not send time to live exceeded message b/c we know TTL only changes when packet is routed so when R1 route the packet TTL will be 0 b/c R1 received it with TTL 1 therefor in that case instead of R1, R2 must be responsible for time to live exceeded message and so for other case TTL 2 R3 must send this type 11 message instead of R2 and so on?
Most operating systems (Windows, Linux, Cisco IOS) will send out three probes by default. Three probes are always sent even if some routers are unreachable.
Hmm, this is a very good question. RFC1812 indicates the following:
A router MUST NOT originate or forward a datagram with a Time-to-Live (TTL) value of zero.
When is the TTL decremented? Well, RFC791 says that this is done every time a module processes an IP packet, which means every time it is routed.
So, if R1 receives the packet with a TTL of 1, it will route the packet (that is, determine the outgoing interface) decrease the TTL, and, according to RFC1812 above, then drop the packet because the TTL is now 0. R1 will then respond to the traceroute with a TTL exceeded message.
Can traceroute be used to check if port is blocked or open, Much like telnet which we use to check if TCP Port is blocked Or Open. Can traceroute be used to check both TCP & UDP As well?
Traceroute for Windows uses only ICMP so there are no Layer 4 ports involved in its operation. On Linux and Cisco IOS, UDP is used, and with each hop, the UDP port is incremented by one. You can specify from which UDP port you will start with, but you don’t know what UDP port will actually be used when you reach the destination since you are not always aware of how many hops away it is.
But even if you know what UDP port will be used by the traceroute when it does indeed reach the destination device, tracroute is not a useful tool to determine if a port is open. First of all because it only uses UDP, secondly because it is difficult to ensure that the right port is being used when it gets to the destination, and thirdly, because the UDP protocol port numbers don’t actually attempt to open a socket when they reach the destination. The port numbers are simply a method of measuring the number of hops.
Telnet would be a more suitable solution, and even better, you can use specialized tools for this specific purpose, such as Nmap.
Hello,
Thank you for your share and availability when we ask our questions.
My question:
I work at ISP:
when I ping URL google.com => don’t work such as DNS is enable.
but our customer, when he tried with his PC ping google.com.. he can reach a server of google.
Other question:
I need to see the number of AS with the name of ISP when I traceroute some destination on Internet.
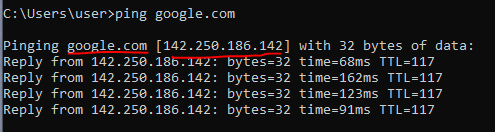
When you ping using a URL such as google.com, the ping operation will use the configured DNS server to try to resolve that URL into an IP address. For example, if I ping google.com from my PC, you can see that the URL has been translated into an IP address:
It seems that when you ping google.com, the ping fails because for some reason the DNS lookup fails. Is it because of your PC? Is it because the ping is being run on a different device that doesn’t have DNS configured? In any case, a PC will always use the configured DNS to resolve the URL. Check to make sure that you too have a DNS server configured.
As far as I know, there is no automated way to discover the AS numbers and the ISPs that you traverse when using traceroute to some destination. The only way you can do this is by using a combination of traceroute, the DNS names of each router that it provides for you, as well as a looking glass server with BGP regular expressions that will filter out the AS paths of particular prefixes. You can find out more information about all of these at the following lessons:
Anyone know what is causing this strange behavior with traceroute -
We have a Firewall and for example when I ping any SVI on a switch located internally on the Lan on a certain subnet they all ping fine as expected from that Firewall.
This is a really basic setup so nothing funky configured anywhere.
We have a basic static route on that Firewall for that specific Subnet telling the firewall if you have anything for that subnet send it out that Lan interface where we have that subnet directly connected, nothing strange there and all basic stuff.
There no ACL’s, route maps or anything funky configured on any of the switches, they are all bog standard.
However when I traceroute to those same SVI addresses from that firewall some of the SVI’s don’t respond and/or they try resolving to public Ip addresses which even at that makes no sense as they show one line of asterix *** and then the resolved name which is in a country far away so even if it was tracing out the WAN surely ip would be more than one hop away.
Granted we are using a non private ip address range on this subnet but it is all “internal” on the LAN.
Why would the firewall try to traceroute some of these SVI’s out on the WAN interface when we have a static route for that entire /16 subnet pointing to an internal interface on the LAN side of the firewall ?
I’m using the SVI ip address of the switches for traceroute so surely the Firewall would just look in its routing table when I run traceroute and see that that SVI ip address is connected to the LAN interface as its been told this from the static route in its table as mentioned above.
Theres no special admin distance or metrics or anything set on the firewall that would tell it to traceroute some of those SVI’s out the WAN link and the rest as normal.
Also what DNS does Traceroute use to resolve the ip addresses along its path ?
For example from a Switch on the network or from a windows pc when you see some of the ip addresses resolving to names, where is this being resolved from ? and is it at all possible that a misconfigured DNS setting could at all effect traceroute in anyway ?
Thanks.
The first thing to think about here is that ping and traceroute are two very different processes, even though they are related. And second, traceroute may be implemented differently depending upon the operating system/manufacturer of the device performing the traceroute.
Ping uses ICMP, and is a purely Layer 3 protocol. Typically you use an IP address as the destination, but a domain name such as www.cisco.com can also be used and resolved in the process.
Traceroute, however, can be implemented using only ICMP, or using UDP in the case of Linux. More details about its inner workings in Windows, Linux, as well as Cisco IOS can be found in the related lesson above.
Now, these differences alone are not enough to bring about the behavior you describe. Even with traceroute, the directly connected network should be chosen over any other default route that may be going out to the Internet.
However, something that may help is to know the vendor of the firewall. Is it an appliance such as PFSense or similar? It may be that the firewall is smart enough in its traceroute implementation, to know the difference between public and private addresses. This is actually a common security feature to protect against what are known as bogons. You can find out more about bogons at this NetworkLessons note. And it may be that it does not have this security feature enabled for the ping feature, but only for the traceroute feature.
Traceroute, as with all applications on the local device, will use the locally configured DNS server to resolve the addresses.
It makes sense, but could you explain why in the lesson example, R2 is answering with a !H ? In that case R2 doesn’t have any route to 3.3.3.3 so it should be * * * ?
Also is this a typo in 1.1 ?
“Above we see that R1 responds with a TTL expired message to S1.” R1 is responding to H1 correct?
When a router does not receive any response from its echo requests sent out using traceroute, this is indicated by an asterisk: *.
When a router receives a response from its echo request from an intermediate router saying that the destination is unreachable, this is indicated by: !H.
In the first case, the router gets no response at all. In the second case it gets a response, albiet the response is from another router saying that the destination is unreachable.
Yes, you are correct, I will let Rene know to make the modification.
If R3 does not have a route back to R1, then the traceroute will fail after reaching R2. In the troubleshooting lab, it is assumed that routing between R1, R2, and R3 has been established. It is only the 3.3.3.3 network that is not included in the routing tables of R1 and R2. That is why once that is added, the traceroute is successful.
I’m thinking out loud here, and would be grateful for any feedback.
Is there any scenario where the ping command would be more useful than the traceroute command? Or wouldn’t it save time if I just used traceroute all the time?
I’m thinking that if I can draw the same conclusions from the traceroute command’s output as from the ping command’s output (that output being if I have a working path towards the destination + if the destination is reachable + the round trip times), plus the additional information of which L3 nodes the packet goes through, then why would I even want to use the ping command? Why wouldn’t I just always use traceroute?
If ping fails, I’ll try traceroute anyway, so why not skip a step? Is it just to save a couple of seconds? Or maybe the mistake in my thinking is that in the long run, I do save a lot more time (and not just a couple of seconds) if I just try the ping command first, before traceroute. Waiting for the output of traceroute can sometimes take longer than the time it takes to first issue the ping command, see it fail, and then issue the traceroute command after the failed ping. So unless I expect all ping commands to fail all the time (or most of them most of the time), I save time in the long run on a mostly working network if I use ping.