That’s an interesting question. I did a bit of research and found that there’s no real reason for this behavior. It is simply the default behavior that Cisco chose to use. You can change this if you like using the allocate global prefix-list command. Other vendors choose to implement this differently, and I think it’s simply a matter of preference.
Yes. For more about the use of RSVP in this role, take a look at this post. MP-BGP is used to exchange VPN labels for MPLS layer 3 VPN about which you can learn more at this lesson:
Implicit null has a value of 3 while explicit null has a value of 0.
A value of 0 represents the “IPv4 Explicit NULL Label”. This label value is only legal at the bottom of the label stack. It indicates that the label stack must be popped, and the forwarding of the packet must then be based on the IPv4 header.
In order for LDP to function correctly, and for MPLS to operate correctly, you require full internal routing within the MPLS core network. BGP will only provide routing for the network edge, that is, the PE routers and the networks they connect. Remember, BGP itself also requires that routing be already established within the MPLS core network either using static routing or some IGP.
You can find more information about it at this Cisco documentation:
Fate sharing involves the creation of shared-risk link groups or SRLGs. These groups are used in situations where links in a network share a common fiber or a common physical path. These links have shared risk, and thus when one link fails, other links in the group also fail.
Using these SRLGs, we can configure auto backup path computation. When fate sharing is activated, links are assigned one or more numbers to represent risks. When two links are assigned a common number then this indicates that these two links are sharing fate. If one of those links fails, then the others, which share the same fate, will also be excluded from the topology. More info can be found here:
Thanks for your post on the site!! I am not able however to find the configurations you are referring to in this particular lesson. Could it be that you are referring to another lesson? Take a look, and if so, let us know the lesson so that we can help you further, and correct any omissions that may be on the lessons…
VPN labels are exchanged between PE routers using MP-BGP. However, this in itself is not enough to get an MPLS/VPN topology working. Although MP-BGP is enough to exchange labels, you still need to determine a Label Switched Path (LSP) to route those labels through the topology. MPLS is still necessary for this. You can find out more about this in detail at the following Cisco community thread:
The thread is quite old, but it is still valid.
It would be helpful if you let us know what it is that you want to achieve. Is there something specific that you need to do? If you let us know, we may be able to help you further.
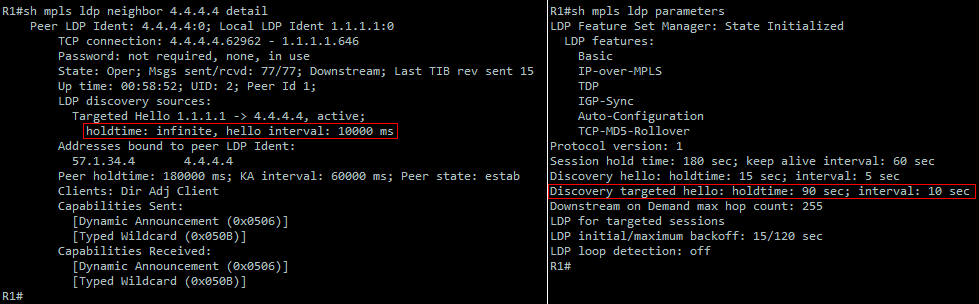
Why is the holdtime from sh mpls ldp neighbor detail is showing infinite.
R1 is configured with static targeted LDP session.
But, if I look from the passive LDP neighbor side, the holdtime is showing 90 seconds.
There’s a good chance that the specific router is configured using MPLS LDP Session Protection. This is a feature that uses targeted hellos to protect LDP sessions. This is explained well in the following Cisco documentation:
Although the targeted hello timer is set to the default of 90 seconds (which is what you see in the LDP parameters output), protection is set up so that this becomes infinite, and that is what you see in the output of the show mpls ldp neighbor detail command.
MPSL labels are not locally significant, because they are shared and used by neighboring routers. They are however locally generated. What does that mean? Well, R1 will look at all the prefixes it has in the routing table and will assign a label to each. That label is generated by R1 without any external influence. However, that label and its associated prefix are shared with its neighbors. That means that if neighbor R2 wants to send a packet to a destination of 1.1.1.0/24 which is a prefix shared by R1, R2 must use the label value advertised by R1 of that particular destination to route it.
So label values are shared and included in LDP updates. If you want to see a packet with a label mapping message content, take a look at this:
For each label mapping, you can see the prefix being shared under the FEC → FEC Elements section of the label mapping message, but you won’t be able to see the actual label because they are encoded as type length values (TLVs).
Hey Rene,
in your conclusion you said “First we send UDP multicast hello packets to discover other neighbors. Once two routers decide to become neighbors, they build the neighbor adjacency using a TCP connection”
However you mentioned comms is formed using udp 646 at the begining. Which is correct?
The hello packets are indeed sent to the 224.0.0.2 multicast address using UDP as the transport layer protocol with a port of 646. Within the hello packet, there is an IPv4 Transport Address TLV. This value is the IP address that is to be used by the router to establish a TCP connection with its neighbor. Once the hello packet is received, the routers create a TCP connection using that IP address.
So the UDP multicast hello using port 646 is just for the hello. Once that’s done, a TCP session is established for all subsequent neighbor communications. Does that make sense?
Hello laz,
could you please explain this text in the lesson, as Rene mentioned labels will be generated for every prefix in the routing table except for BGP prefixes, I understand that but why ?
Typically, the reason for not using LDP for BGP prefixes is due to the use of BGP itself for label distribution in MPLS networks, more specifically through an extension of BGP known as Multiprotocol BGP or MP-BGP.
MP-BGP is used when MPLS is employed over BGP because it supports multiple network layer protocols, not just IPv4. This includes the distribution of label information using BGP NLRIs.
For the specific case of VPNs, BGP is used to distribute VPN label information between PE routers, enabling MPLS VPN services over BGP.
The key reason behind this is control and flexibility. BGP allows more control over path selection based on policy (as opposed to just shortest-path), and allows the network to scale to larger sizes. When running MPLS in conjunction with BGP, network engineers have greater flexibility and control over traffic engineering, quality of service, and other advanced features. BGP also allows for complex scenarios like inter-AS MPLS VPNs.
So to conclude, labels aren’t generated for BGP prefixes with LDP because BGP itself (more specifically, MP-BGP) is used to handle label distribution for these prefixes. Does that make sense?