Hello José
I believe this has to do with the IOS version you are using. Can you share with us the output of your show version command?
Laz
Hello José
I believe this has to do with the IOS version you are using. Can you share with us the output of your show version command?
Laz
Hello @ReneMolenaar You’re articles are amazing. I have a question regarding “priority” command for QoS, as far as I understand, this commands put specific class to LLQ. In your article you mentioned “The Kbps rates that I configured are not hard limits. When there is no congestion on the interface, both classes can get more bandwidth.” But as I know, for priority it’s actually should be hard limit, because since this queue is emptied first, then we can see the situation, that other queues will never be served and to avoid this situation, priority sets hard limit for traffic in LLQ. Can you please clarify? Thank you.
Thanks Rene for your explanation , it was really helpful for me. however I have one inquiry to link all concepts with real network environment.
classification and marking we should implement it on the stub routers . and the routers in between we should implement queuing Policy like QOS LLQ.
Hello Ammar
Generally speaking, best practice dictates that you should classify and mark traffic as close as possible to the source. In many cases, this means that it should indeed take place at the stub routers, but this highly depends on your topology.
Secondly, in general, intermediary routers, such as those within the core and distribution networks, should have queuing policies such as QoS LLQ implemented. This is a general rule of thumb that you can use. However, keep in mind that depending on the topology and your requirements, some level of differentiation to this general rule may be needed. So you have to take it on a case-by-case basis.
I hope this has been helpful!
Laz
Hello, everyone!
If we define classes and setup CBWFQ and there is no congestion, won’t the default queuing mechanism be FIFO? So first-in first-out.
My next question is, if we define 3 classes with the following bandwidth reservations
CLASS-A → 40%
CLASS-B → 40%
CLASS-C → 20%
If the queue for CLASS-A happens to be empty or has spare bandwidth while CLASS-C has a lack of it, can CLASS-A provide some of its bandwidth to CLASS-C?
About LLQ, if we give a specific % of bandwidth to the LL queue, does that mean that we’ll guarantee that specified amount of bandwidth, but no more than that during times of congestion? Because if other queues have bandwidth to spare, and they provide it to the LL queue, they could, again, starve themselves.
And my final questiion is

This command basically tells the router that the queue for this specific class should use LLQ and be considered a priority queue. The “2000” specifies the size of the priority queue, the maximum, correct?
However, Rene mentioned that we also have to configure policing for the LLQ to prevent it from starving the other queues. However, if we have already specified the maximum amount of bandwidth that this queue can use using this command, doesn’t that effectively prevent the queue starvation?
Thank you very much!
David
I have a question regarding of how I must view the bandwidth values in the policy-map configurations:
Does that mean it’s the maximum capacity of the queue in terms of how many packets i can store or is that the actual speed which we set to forward the packets out of this queue? I think it’s the actual size of the queue, right?
Kind regards,
Mirko
Hello, everyone!
I have a few questions about these config opportunities:
So first question: Which mainly belongs to all of them:
So I know that with the priority command i “activate” the LLQ scheduler.
Now if the traffic would go over the configured rate, but bandwidth would be available from other queues (CBWFQ or other LLQ) it cannot use it, so we don’t starve out other queues. Basically because with the priority command we specify a maximum bandwidth guarantee no?
Next question is, I interpret the priority command and the priority rate and priority percent rate commands different.
If I would give the priority command, I would always (also if everything is normal and the interface isn’t congested) use LLQ and not FIFO.
However with the priority rate command I would use this all the time too but my policer only gets active during times of congestion.
With the command: priority percent rate its also always active so we use LLQ, but we only police it during times of congestion.
Is that right or am I missing something?
And also what does “strict” mean in this context? For me it means we use LLQ regardless of congestion is happening or not.
Thanks in advance,
Mirko
Hello Mirko
In the context of QoS LLQ, the bandwidth values you see in the policy-map configurations relate to the actual speed or rate at which packets are sent out of the queue, not the size of the queue in terms of packet storage.
When you configure a policy map and specify a bandwidth for a particular class within the policy map, you are essentially telling the router to reserve that amount of bandwidth for that class under congestion conditions. It’s a way to guarantee that certain traffic (like voice or critical data) will have a certain amount of bandwidth available even when the network is busy. Remember, QoS is all about reserving and guarenteeing bandwidth for particluar packets.
LLQ is specifically designed to provide strict priority queuing for delay-sensitive traffic like voice or video. The traffic that falls into the LLQ is given priority over all other traffic, up to the amount of bandwidth specified by the priority command. This means that the LLQ will be served before other queues, and up to the configured rate, before other classes are able to send traffic.
So the bandwidth command in a policy-map class specifies the rate at which packets are forwarded out of the queue. It is not a storage size limit for the queue itself. The size of the queue, which determines how many packets it can store, is configured separately, often with the queue-limit command. The default queue-limit is typically 64 packets on most platforms, but can be adjusted. An excellent Cisco resource on understanding the queue limits and output drops can be found here:
I hope this has been helpful!
Laz
Hello Mirko
Take a look at the answer found here:
I hope this has been helpful!
Laz
Hello David
Actually, if there is no congestion, there is no queuing. Queuing only occurs if a packet arrives for egress at an interface and cannot be immediately sent due to the traffic volume. It will then be placed in a queue (hence the name “queuing”). If there is no congestion, it will not be placed in a queue thus it will not be queued. It will be immediately sent. A more appropriate phrase to use is that in the absence of congestion, packets are served on a “first come first serve” basis.
First of all, the bandwidth reservations are different and distinct from queues. Queues contain packets that can’t be immediately sent, while bandwidth allocations are the minimum guaranteed traffic that will always be available to those types of packets. So in this context, your question is probably “If the class C bandwidth allocation has been reached, and the class A bandwidth allocation has not been reached, will Class C packets begin to be queued or can they immediately use the available bandwidth from the Class A allocation?”
CBWFQ does not allow direct borrowing from one bandwidth allocation to another. However, it does detect what the current total available bandwidth on the interface is. This excess bandwidth can be distributed among the classes. However, this distribution is based on the weights or priorities assigned to each class, not on a “borrowing” mechanism where one specific class can directly take unused bandwidth from another.
Again remember the distinction between bandwidth allocation and queuing. By assigning a certain percentage of bandwidth to the LLQ, we are guaranteeing that percentage as a minimum bandwidth that will always be available to that type of traffic. If that bandwidth percentage is exceeded by priority traffic, and the bandwidth of other classes is not, then LLQ does use some of the available bandwidth. However, how it actually behaves depends upon if there is congestion at the time or not. It is not just a simple usage of free bandwidth. It follows a complicated algorithm that may result in some dropped packets. Take a look at the following Cisco community thread that sheds more light on this:
It all depends on the balance of values that you use. If you allocate too much bandwidth to the LLQ (say 50 to70%) and you have priority traffic continually coming on that interface, you will only have 50 to 30% of the bandwidth available for everything else. This can result in congestion, and all of the rest of the CBWFQs filling up, resulting in starvation. Simply specifying a maximum amount is not enough to stop starvation in this case. One option is to lower the allocated bandwidth to the LLQ, while the other is to enforce policing thus limiting the maximum amount of time that the LLQ is preferred over all others. That way, the scheduler will always try to empty the priority queue first unless it has exceeded its policed amount. That provides the opportunity to the other priorities to get serviced as well. What to use depends upon the nature of the traffic and the expected % of priority traffic.
I hope this has been helpful!
Laz
Hi Rene
i hope you’re doing great. i have a question which is based on this <<DSCP EF (46) is 101110 in binary, that’s 184 in decimal >> please can tell how did you get the decimal value .
thanks, chris.
Hello Chris
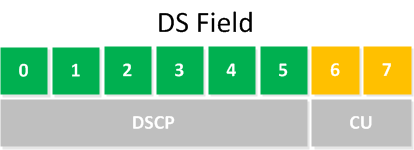
If you take a look at the full DS field, you will see that it is 8 bits in length. As shown below, it is separated into two portions, the DSCP and the CU:
CU stands for “Currently Unused” so those two bits are always set to 0. More about the DS field can be found in this lesson.
Now, if the value of DSCP is EF (46) in binary is 101110. That’s 46 in binary, and it’s 6 bits because the DSCP portion of the DS field is 6 bits.. However, for the purposes of generating a ping with a ToS value, we must put in the decimal value of the whole DS field, which is 8 bits. So you must add the two zeros at the end that correspond to the CU. This results in 10111000. If you convert that to decimal you get a value of 184.
Let’s take a look at CS3 (24) in the lesson as well. The value of the DSCP is 24 which in binary is 011000. We add the two zeros of the CU portion and we get 01100000 as the value of the full ToS 8 bit field, which is a value of 96, which is what appears in the lesson. Does that make sense?
I hope this has been helpful!
Laz
Hi Laz, I hope you’re doing great.I still don’t get it. Can you please show me the DSCP and CU value and how did you to calculate them.
Thank you so much
Happy new year ![]()
Hello Chris
Sure, no problem. The whole issue here has to do with how the extended ping command interprets the value you put in for the ToS field. When you issue an extended ping, one of the parameters you can add is the 8-bit value of the ToS field. However, the definition and use of this particular field in the IP header has evolved over the years, and part of that change has to do with the names and the definition of specific bits within the field. The field is now called the DS field, and it’s composed of two sub-fields, the DSCP, and the CU. Therefore, we must make sure that the value we input will be correctly interpreted. The field is an 8-bit field, composed of those two sub fields, but the extended ping needs us to input that value in decimal.
If we want to define a ping with a particular DSCP value, we must convert that particular DSCP value to the decimal number created by the full 8-bit ToS field. So if we have a DSCP value of EF (46), that’s 46 in decimal. Remember, the DSCP value is 6 bits in length, so in binary that’s a value of 101110. Now look at our ToS field again (which is now called the DS Field):
Now this 6-bit value represents the leftmost 6 bits in the 8-bit ToS field, right? The CU is always 00 for the reasons I explained in my previous post. So the full 8-bit ToS field will be the concatenation of 101110 and 00 which is 10111000. Translating this 8-bit value to decimal is 184. So in the extended ping, we will use a value of 184 for the ToS. Thus the ping that will be sent will have EF(46) set in the DS field. Does that make sense?
I’ve created a NetworkLessons note on the topic as well that may help to clarify further.
I hope this has been helpful!
Laz
Hello laz
thank you so much for your explanation. i understood.
DSCP Dec ToS value IP Prec
0 0 0
8 32 1
10 40 1
14 56 1
18 72 2
22 88 2
24 96 3
28 112 3
34 136 4
36 144 4
38 152 4
40 160 5
46 184 5
48 192 6
56 224 7
you did use the value of tos bytes. thanks again
chris
Hi Guys,
Wondering if LLQ can be applied inbound as well? I am getting the following error in cisco IOS XE when including a priority parameter in my policy-map for the class-map it’s referencing..
-POLICY_INST_FAILED: Service policy installation failed on GigabitEthernet1. service-policy not applicable for interface features. policy:test_app, dir:IN, ptype:, ctype:DEFAULT
Hello Nicolas
LLQ can only be applied to outbound traffic on an interface. This is because you can only control how traffic leaves your network, not how it enters. The error you’re getting is because Cisco IOS XE does not support applying service policies with the priority command (used for LLQ) in the inbound direction.
For inbound traffic, you can use other QoS mechanisms like policing or shaping to manage how traffic is treated when it arrives on your device.
I hope this has been helpful!
Laz
Hi Laz, thank you for the response and confirming this. So with that in mind , say I want to apply qos on a wan link between datacenters but I only want my qos to take effect when there’s congestion ( when the link is at max capacity ) , so in other words " congestion management " .. what is the best approach to do this for inbound traffic if priority queuing in general is a feature that’s only available for outbound traffic ?
Hello Nicolas
Let me clarify one issue that I mentioned before. For ingress traffic, network devices generally do not have control over the rate at which packets arrive. Therefore, shaping, which involves delaying and scheduling packets, isn’t feasible for incoming traffic. Instead, policing is used to either drop or mark packets that exceed the bandwidth profile, as buffering large amounts of incoming traffic to shape it would be impractical and could lead to high latency or buffer overflows.
Now concerning your question, typically QoS mechanisms kick in whenever there is congestion. Whenever there is no congestion, traffic will simply be forwarded as soon as it arrives, in the order it arrives. Since there is no congestion, there is no delay. QoS is really only meaningful when there is congestion.
So to answer your question, on ingress, as mentioned before, only policing has any practical application. If you want to have more control over how such traffic is being transmitted, and how it arrives on the interface of a device, it would be preferable to apply any congestion management QoS mechanisms on the outgoing interface of the directly connected device. That’s not always possible, as sometimes this device belongs to the ISP. In such cases, you would have to negotiate with the ISP to ask them to set up the rate at which you want your traffic to arrive.
I hope this has been helpful!
Laz
Thanks Laz, I have control over the transport routers whom aren’t shared with anyone else. All we’re doing is leasing the fiber from the ISP
So to summarize what you’re saying:
1 - LLQ should only be applied on outbound traffic, not inbound
2 - Policing is a better mechanism to control the manner incoming packets are processed on the interface because in an event where there’s congestion on the link, packets that are in violation of the traffic contract can be dropped based on specific markings and/or how they’ve been categorized ( Conforming, Exceeding , Violating)
3 - Shaping introduces risk to the link because it could potentially lead to higher latency and/or buffer overflows. This makes sense considering the CIR takes into account your “outbound bandwidth” & not “inbound”. You’re basically balancing the need for traffic control with the risk of introducing latency and buffer issues. Incoming traffic is also determined by the sender, and you can’t proactively delay or schedule packets before they even reach your network… now in my case , we’re taking cross-site traffic but we’re only introducing this control on the transit link , not at the access and/or distribution layer
Overall QOS only kicks in when there’s congestion and as a best practice it is better to configure it on the egress interface of each link, not ingress.